

High level programmable, modern baseband processor for a broad range of signal processing and control workloads
Ceva-BX2 baseband processor is a multipurpose hybrid DSP and Controller,...
The World’s Most Powerful Baseband Processor
The Ceva-XC16 is the world’s strongest and fastest vector DSP, built upon the innovative Gen4 Ceva-XC™ multithread architecture. It is ideally suited to handle the advanced baseband computing needs of modern 5G base station RAN architectures.
Being a scalable and flexible SDR 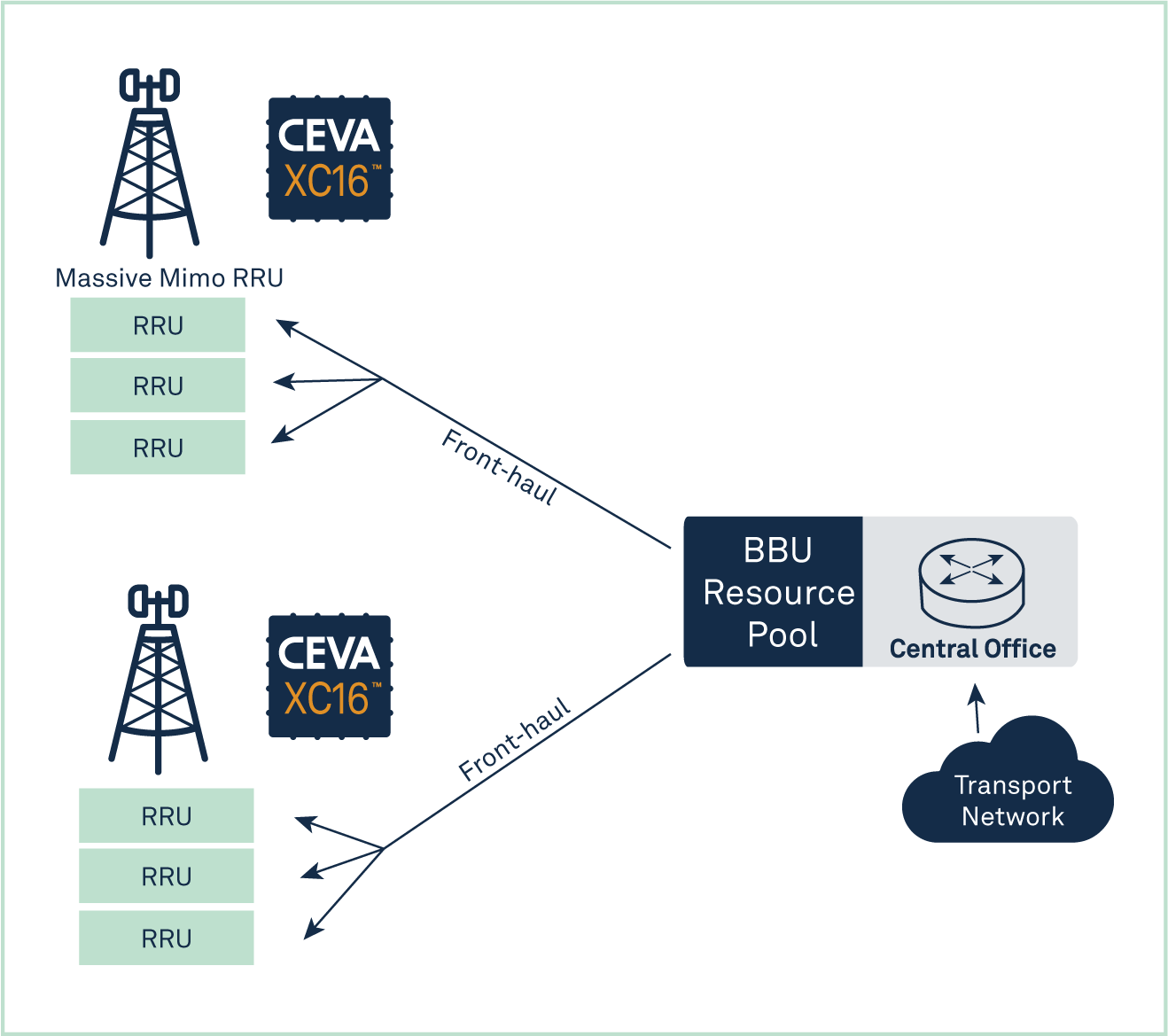 platform, the Ceva-XC16 can be customized, configured and scaled to address multiple applications, including massive baseband (BBU) aggregation and processing, DU acceleration, OpenRAN deployments, massive MIMO RRUs, multi gigabit modems and ultra-low latency use cases, as well as enterprise and high-end 802.11ax Wi-Fi access points.
platform, the Ceva-XC16 can be customized, configured and scaled to address multiple applications, including massive baseband (BBU) aggregation and processing, DU acceleration, OpenRAN deployments, massive MIMO RRUs, multi gigabit modems and ultra-low latency use cases, as well as enterprise and high-end 802.11ax Wi-Fi access points.
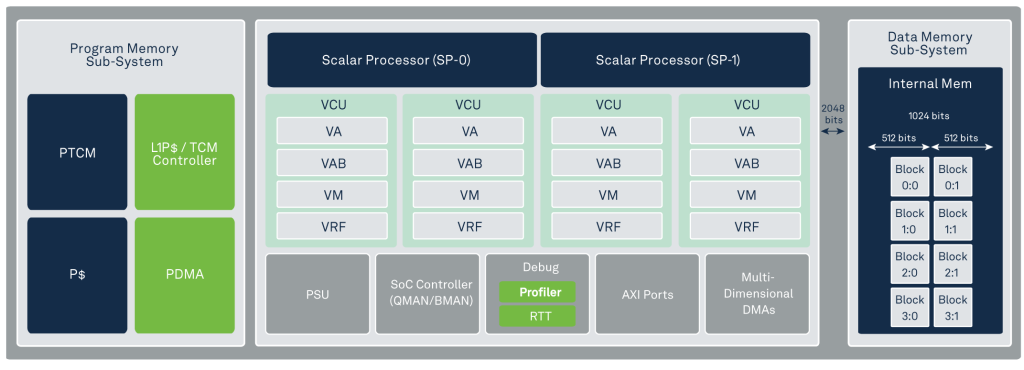
The Ceva-XC16 DSP is based on a unified scalar and vector-processing platform, using two independent scalar cores, sharing the same coherent tightly coupled memory sub-system, to facilitate true simultaneous and symmetric multithreading operation. Combined with an innovative dynamic multithread Vector Compute Unit (VCU) resource allocation scheme, it achieves unparalleled efficiency in VCU usage, handling large multi-user allocations and ultra-short latency. This results in fine resolution of resource allocation in both time and frequency, as is required in modern 5G base stations and Wi-Fi baseband processing applications.
The Ceva-XC16 uses deep pipeline and innovative physical design methods that enables it to achieve unparalleled 1.8GHz clock speeds at 7nm process node, clocking a 256 MAC VCU and 2048-bit wide memory access bandwidth, amounting to the world’s most powerful baseband crunching machine, achieving up to 1600 Giga Operations Per Second (GOPS).
The dual scalar DSP cores are based on the Ceva-BX architecture, enhanced to meet the high speed of 1.8GHz. These provide a 30% improvement in both control code efficiency and code size relative to previous Ceva-XC generations.
The new design concepts boost the performance per area for a typical 5G use case by 50%, which amounts to 35% die area savings for a large cluster of cores, as is typical for many wireless baseband processing infrastructure use cases.
Benefits
Designed to meet the demanding requirements of modern 5G networks for extreme multi gigabit, multi carrier and user, and ultra-short latency baseband computing
Scalable architecture addresses the full range of eNodeB and gNodeB baseband processing needs, from D-RAN to C-RAN and V-RAN, DU acceleration, OpenRAN architectures, as well as self-contained small and femtocell configurations
World’s strongest baseband computing platform, running at 1.8GHz in 7nm, delivering 2.5X performance gain and 35% performance/area savings compared with its predecessor
Innovative dynamic multi core architecture, utilizing two scalar control processors, enabling true simultaneous multi thread operation with dynamic VCU resource allocation
Main Features
- Core features:
- Fully programmable DSP architecture incorporating unique mix of VLIW and SIMD vector capabilities
- Deep pipeline architecture achieving very high speeds for the most extreme use cases
- 8-way VLIW provides optimal hardware utilization
- Dual scalar processors for running true multi-threading on common memory sub-system, with dynamic VCU resource allocation per thread
- Extremely powerful vector processor supports fixed- and floating-point operations with 256 MACs per cycle and 2048-bit wide memory BW, achieving 1600 GOPS
- Utilizing new generation dual Ceva-BX cores with optimizing LLVM C compiler for protocol, control, and DSP native C code supports very low overhead RTOS multi-tasking with dynamic branch prediction. Achieving 30% performance gain and 30% code reduction relative to previous generation core
- New and improved ISA for accelerating FFT and symmetric FIR
- x2 improvement in complex FIR and matrix manipulation vs previous generation
- System features:
- Core streaming interfaces support ultra-low latency
- AMBA 4 compliant matrix interconnect
- Comprehensive multicore support with ACE-compliant cache coherency
- Hardware/software partitioning delivers exceptional power efficiency while maintaining software flexibility with Queue and Buffer Managers and auxiliary AXI ports supporting multi dimensional DMA
Block Diagram
Ceva-XC16 Stays Ahead of 5G Rollout
Dynamic Multithread Capability Boosts New Radio Architectures
The Ceva-XC16 DSP is the first product to implement Ceva’s fourth-generation XC architecture, which includes a new dynamically configurable multicore/multithread feature.