


Environmental Noise Cancellation voice processing software package providing bi-directional enhanced speech clarity and intelligibility for resource-constrained devices
Clear speech is...
A modern, high performance Sound DSP, optimized for far-field noise reduction
Ceva-BX2 is a high performance sound DSP, designed for intensive Audio applications such as:
- Voice assistants with multi-microphone beamforming and noise reduction
- Speech recognition engines (ASR) for voice trigger and commands
- Object based audio rendering and 3D Audio processing
- Natural Language Processing (NLP) at the edge
- Sound sensing and analytics using neural networks
The Ceva-BX2 sound DSP is targeted for high performance audio devices such as DTV, Smart Speaker, Soundbar, and car infotainment systems.
Ceva-BX2 uses quad 32X32-bit MACs and octal 16X16-bit MACs, with enhanced capability for supporting 16×8-bit and 8×8-bit MAC operations.
The Ceva-BX2 is using an 11-stage pipeline and 5-way VLIW micro-architecture, it offers parallel processing with dual scalar compute engines, load/store and program control that reaches a speed of 2 GHz at a TSMC 7nm process node.
The Ceva-BX2 Instruction Set Architecture (ISA) incorporates support for Single Instruction Multiple Data (SIMD) as well as optional floating point units for high accuracy algorithms.
The Ceva-BX2 is accompanied by a comprehensive software development tool chain, including:
- Advanced LLVM compiler
- Eclipse based debugger
- DSP and neural network compute libraries
- Neural network frameworks support
- Real Time Operating Systems (RTOS)
Benefits
Ceva-BX2 combines low power Sound DSP kernels execution with real time control capabilities and compact code size
Up to 16 GMAC/sec tailored for sound neural networks
High-throughput DSP addresses advanced applications
Ceva-Connect offloads the processor from data transfers to hardware accelerators and peripherals
Main Features
- Octal 16x16 MACs
- Quad 32x32 MACs
- 5-way VLIW
- 8/16/32/64-bit data types
- 16x8 and 8x8 Neural Network support
- Half, single and double precision IEEE floating point units
- Innovative Branch Target Buffer minimizing branch overhead
- Hardware loop buffer for reduced power consumption of code loops
- High performance controller
- 5.46 CoreMark/MHz
- Dynamic branch prediction
- Full RTOS support
- Compact code size
- Advance system control
- Automatic Queue and Buffer management mechanisms to integrate co-processors and create a cluster of Ceva-BX cores
- Dedicated HW accelerator ports
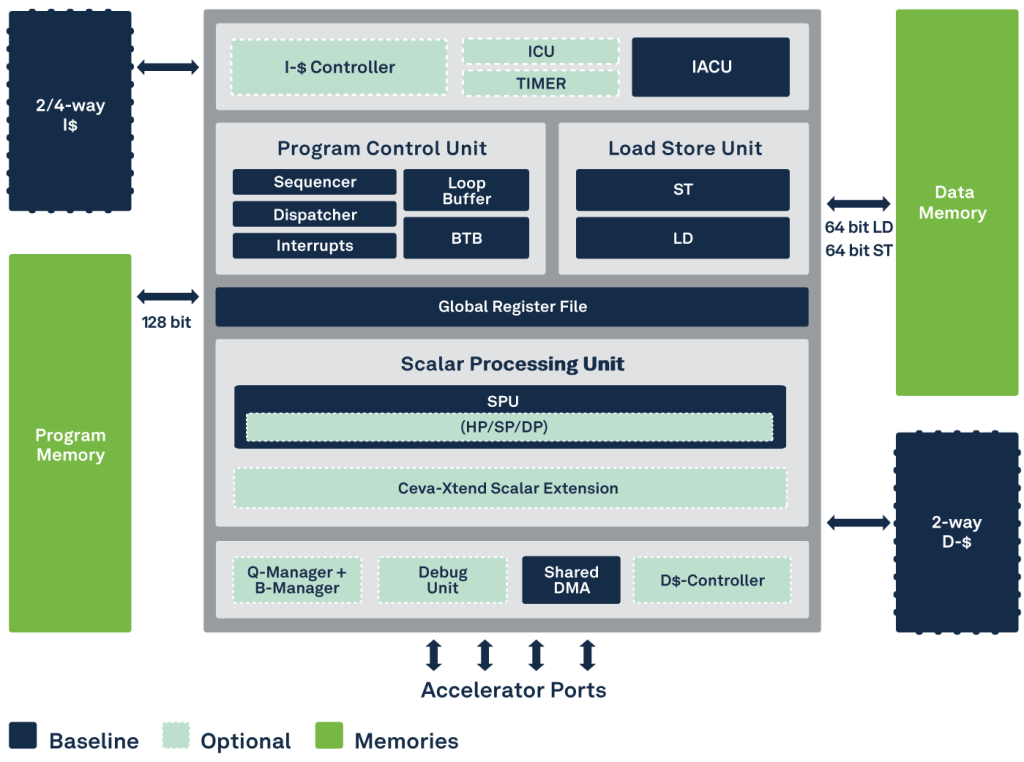
Block Diagram
3D Audio technology and emerging applications for immersive listening experience

Join Ceva and VisiSonics experts to learn about:
- Multichannel Audio and Ambisonics
- 3D Audio Applications and markets
- HRTF and Head-tracking for 3D Audio