


Environmental Noise Cancellation voice processing software package providing bi-directional enhanced speech clarity and intelligibility for resource-constrained devices
Clear speech is...
A modern audio DSP, designed for battery operated, high-performance, audio and voice applications
Ceva-BX1 is an ultra-low-power Audio DSP, designed for:
- Bluetooth earbuds and headsets using audio over BLE/BTDM
- Voice control IoT with always-on speech recognition
- Object based audio rendering and 3D Audio processing
- Sound sensing in mobile, headsets and wearables
- Audio codecs and high quality Audio post processing
Ceva-BX1 inherent low power design and compact code size make it ideal for a broad range of advanced audio/voice applications, requiring signal processing and real-time control workloads.
Ceva-BX1 audio/voice DSP is targeted for CE devices with power constraints in mind. TWS earbuds, Smart Home, IoT, Mobile and Wearables are among the devices to benefit from the Ceva-BX1 performance.
Using dual 32X32-bit MACs and quad 16X16-bit MACs, the Ceva-BX1 serves low to mid-range DSP workloads, such as multi-microphone noise reduction, light AI processing and always-on sensor fusion, with up to 8 GMACs per second. The Ceva-BX1 is using an 11-stage pipeline and 4-way VLIW micro-architecture, it offers parallel processing with a scalar compute engine, load/store and program control that reaches a speed of 2 GHz at a TSMC 7nm process node.
The Ceva-BX1 Instruction Set Architecture (ISA) incorporates support for Single Instruction Multiple Data (SIMD), as well as half, single and double precision floating point units for high accuracy sensor fusion and positioning algorithms.
Security is addressed using dedicated trusted execution modes to comply with the stringent safety standards.
The Ceva-BX1 audio DSP is accompanied by a comprehensive software development tool chain, including:
- Advanced LLVM compiler
- Eclipse based debugger
- DSP and neural network compute libraries
- Neural network frameworks support
- Real Time Operating Systems (RTOS)
Benefits
Ceva-BX1 combines low power audio DSP kernels execution with real-time control capabilities and compact code size
Easily applied to a wide range of wearables and always on IoT applications
Compact and efficient single core solution
Highly scalable application-specific instruction set
Main Features
- Quad 16x16 MACs
- Dual 32x32 MACs
- 4-way VLIW
- 8/16/32/64-bit data types
- 16x8 and 8x8 Neural Network support
- Half, single and double precision IEEE floating point unit
- Innovative Branch Target Buffer minimizing branch overhead
- Hardware loop buffer for reduced power consumption of code loops
- High performance controller
- 4.41 CoreMark/MHz
- Dynamic branch prediction
- Full RTOS support
- Secured execution modes
- Compact code size
- Advance system control
- Automatic Queue and Buffer management mechanisms to integrate co-processors and create a cluster of Ceva-BX cores
- Dedicated HW accelerator ports
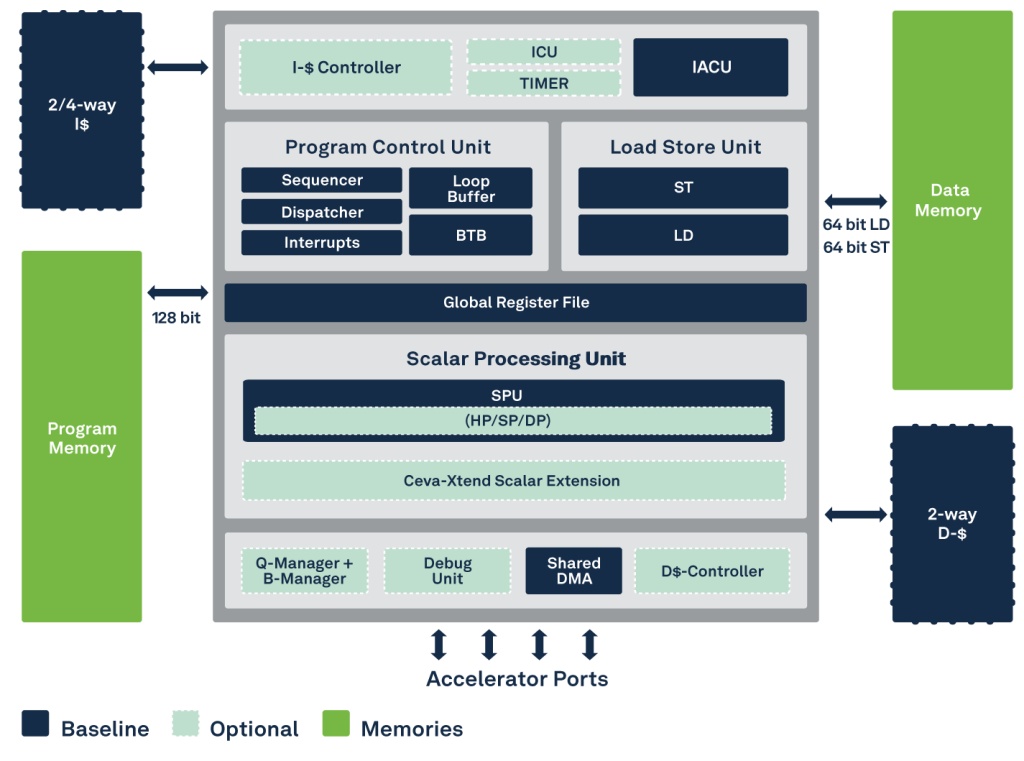
Block Diagram
3D Audio technology and emerging applications for immersive listening experience

Join Ceva and VisiSonics experts to learn about:
- Multichannel Audio and Ambisonics
- 3D Audio Applications and markets
- HRTF and Head-tracking for 3D Audio