













What does your device need to do with the data it gathers from sensors? Our latest blog post explores different data processing strategies to help you choose the right approach for your application.
Thursday, April 11, 2019
What level of intelligence and data processing does your device really need? Does machine learning make sense? Which approach is most appropriate for you?
Let’s look at two different data processing methods: state estimation using Kalman filters and pattern matching with machine learning.
State Estimation Using Kalman Filters
Sensor data is often used for state estimation. For example, a primary goal in robotics is to estimate the pose of the robot in the real world, where pose is position and orientation (6DOF, or degrees of freedom). The robot fuses data from sensors such as an IMU (inertial measurement unit), wheel encoders, cameras, and other sensors to calculate the pose. The pose needs to be calculated in real-time, as the device moves with typical update rates on the order of 100 Hz.
Sensors each have their own strengths and weaknesses. By fusing data together and not relying on a single sensor, we can achieve a better estimate of the robot pose (state) with less uncertainty. For example, the IMU can almost directly measure tilt and heading, while processed data from a camera can be applied to measure tilt, heading, and linear position. For more information about sensor fusion, view our webcast, Using IMUs and Sensor Fusion to Unlock Smarter Motion Sensing.
There are many algorithms for fusing data from multiple sensors, but a good Kalman place to start is the Kalman filter. Kalman filters are conceptually simple and are great for combining information when dealing with uncertainty. Also, Kalman filters have small computational requirements and converge quickly, so they are typically easy to embed on low power devices.
Without going into all the math – I know you are probably disappointed – the Kalman filter works by creating a motion model and a measurement model, both of which are probability distributions. In the context of our robot example, the motion model describes the pose of the robot over time with its uncertainty. The measurement model describes how we model sensor measurements with their own uncertainty. Using both the motion model and measurement model, we can more accurately estimate the robot pose as shown in the figure below.
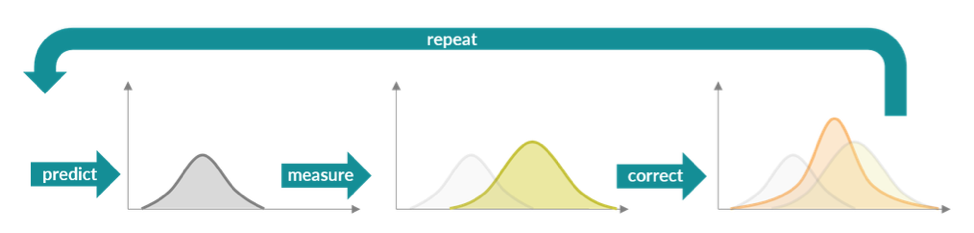
- We maintain a motion model and make predictions of the new state based on our previous state information and knowledge of the system. For example, our robot may have a known maximum velocity as well as acceleration/deceleration that will impact our prediction (in gray).
- We take sensor measurements that will adjust our state estimate based on those estimates and sensor uncertainty (yellow).
- We combine those together to correct our state estimate (orange).
Kalman filtering is an excellent starting approach for modeling problems such as state estimation and sensor fusion. In fact, the original Kalman filter is an optimal estimator for linear systems with Gaussian error.
Unfortunately, most real-world systems are non-linear, and you may need to consider other approaches. In these cases, you might consider Extended Kalman Filters, Unscented Kalman Filters, or particle filters for your application. Some cases may require unique, proprietary algorithms to optimize for a particular use-case to achieve the best performance.
Pattern Matching with Machine Learning
Machine learning (ML) is a category of algorithms that enable computers to identify patterns in data and make inferences with new data, all without requiring explicitly programmed rules. Machine learning is considered a subset of artificial intelligence (AI), although it has become synonymous with AI over the last couple of years, with advances in deep learning and image recognition and the hype surrounding its success.

Source: Picture from Machine Learning for Humans https://medium.com/machine-learning-for-humans/why-machine-learning-matters-6164faf1df12
Within machine learning, there are various types of algorithms including supervised and unsupervised techniques. Supervised learning takes labeled training data and learns a function mapping from the inputs to the outputs.
Y= f(X)
The goal is to find a function that minimizes the error for the training data but also generalizes well enough for new data with overfitting.
With unsupervised learning, there is no Y! That is, there is no training data and no labeled output from which to make inferences. Rather, the goal is to learn relationships within the raw data without prior knowledge. Unsupervised techniques are useful for applications like recommendation engines that try to find underlying relationships between content and then use that information to make suggestions (e.g., you might like this if you also like that, based on similar users).
For sensor data processing, it’s often the case that supervised learning is more appropriate for the job at hand, which is often to classify information or detect events. In both cases, there is a model between the input data (X) and the desired output data (Y) that we need to create to make predictions.
Let’s consider the example where we want to detect an anomalous condition (pattern) using data from multiple sensors. The output is a classification value indicating whether or not the condition exists. Classical supervised machine learning techniques include logistic regression and support vector machines (SVM). In these cases, we extract features from our sensor data and correlate these against truth data indicating whether the condition exists or not (training). Again, the goal is to identify a function that uses the features (X) to best predict the classification (Y).
Logistic regression and SVM use different techniques to separate the classifications to minimize error, the former being more probabilistic in nature and the latter more geometrically motivated. In short, logistic regression is more appropriate when the data relationship is linear and with fewer dimensions, while SVM works better for cases with multi-dimensional data or relationships that are non-linear.
Deep learning using neural networks is a more modern option for supervised learning, but to work effectively it requires lots of labelled training data. Generally speaking, neural networks are universal approximators for nonlinear functions, which means they can better approximate real-world data and as a result, are finding more and more uses.
The tradeoff is in the training process and cost. Not only is there a need for much more data, but the process of training a neural network is often opaque with many knobs and few insights into how those knobs affect final performance. But deep learning neural networks are great for real-time visual translation of foreign languages, detecting abnormal heart rhythms, and finding undiscovered exoplanets. And they may be appropriate for sensor data classification problems where you don’t know the features that will help predict the classification. In deep learning, the neural network finds those features on its own.
What Does Your Product Need?
There is no one right answer for how to process data. It will all depend on the needs of your application. Start by asking yourself what your customer really needs and what your application constraints are, and build backwards from there.
With this information in mind, you can start to make sense of the technologies available to you and what will be most beneficial to your end product. If you have questions, contact the team at Hillcrest Labs. We’re happy to share our sensor fusion expertise and help guide you in the right direction, regardless of which AI approach you decide to take.
Learning More
Kalman filtering resources:
Machine learning resources:
You might also like


More from Sensor fusion

Evaluating Spatial Audio – Part 1 – Criteria & Challenges
We here at Ceva, have spoken at length about spatial audio before, including this blog post talking about what it …

Gyro Pen Revolution: From Passive Stylus to Motion Pen
Imagine you’re a school teacher using the latest technology to engage your students. The class thrives on interactive presentations and …

How Head Tracking Can Elevate Your Spatial Audio Experience
Imagine you are walking down the street, and you hear someone call your name from your right side. You turn …