













Object detection and recognition are an integral part of computer vision systems. In computer vision, the work begins with a breakdown of the scene into components that a computer can see and analyse.
The first step in computer vision—feature extraction—is the process of detecting key points in the image and obtaining meaningful information about them. The feature extraction process itself comprises of four basic stages: Image preparation, key points detection, descriptor generation and classification. Practically, the process examines each pixel to see if there is a feature present in that pixel.
The feature extraction algorithms describe the image as a set of feature vectors that point to key elements in the image. This article will review a number of feature detection algorithms, and in that process, see how object recognition in general and feature recognition in specific have evolved over the years.
Early Feature Detectors
Scale Invariant Feature Transform (SIFT) and Good Features To Track (GFTT) were early implementations of the feature extraction technology. However, these algorithms were computationally intensive and involved heavy floating-point calculations, so they weren’t the best fit for real-time embedded platforms.
Take SIFT for instance, a highly accurate algorithm that produces good results in many use cases. It finds features with sub-pixel accuracy but only keeps corner-like features. Moreover, while SIFT is very accurate, it’s also very complicated to implement in real-time and usually uses low input image resolution.
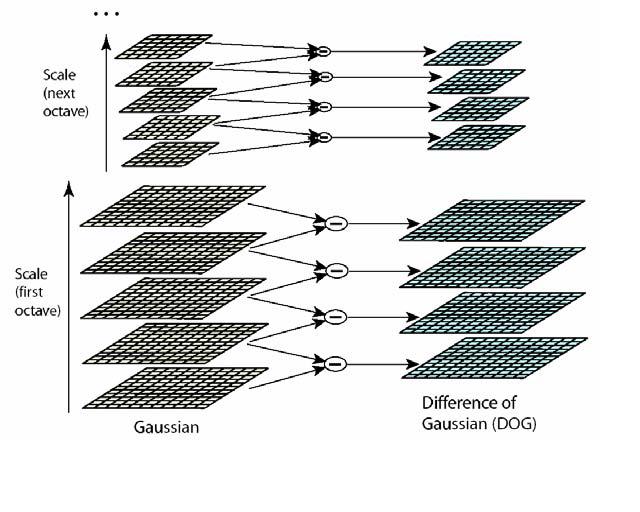
SIFT is a computationally intensive algorithm
Therefore, SIFT is less common today and is mostly used as a reference to measure the quality of new algorithms. The need to reduce the computational complexity eventually led to development of new sets of feature extraction algorithms that are more implementation sensitive.
Second-Generation Algorithms
Speeded Up Robust Features (SURF) is one of the first feature detectors that has been built with efficient implementation in mind. It replaces computationally expensive operations in SIFT with a series of additions and subtractions in different rectangle sizes. Moreover, the operation is easy to vectorize and has low memory requirements.
Next, Histograms of Oriented Gradients (HOG), the popular pedestrian detection algorithm commonly used in the automotive industry, can vary to include different scales to detect objects in different sizes and use the amount of overlap between blocks to improve detection quality without an increase in computation. It could make use of parallel memory access, which unlike conventional memory systems that process one lookup table at a time, speeds up the results according to the level of memory parallelism.
Then, there is Oriented FAST and Rotated BRIEF (ORB), an efficient alternative to SIFT that uses binary descriptors for feature extraction. It combines the addition of orientation to the FAST corner detector and rotating the BRIEF descriptor to align it with the corner direction. The combination of the binary descriptor and the use of low weight functions like FAST and Harris Corner yield a very computationally-efficient and fairly accurate descriptor map.
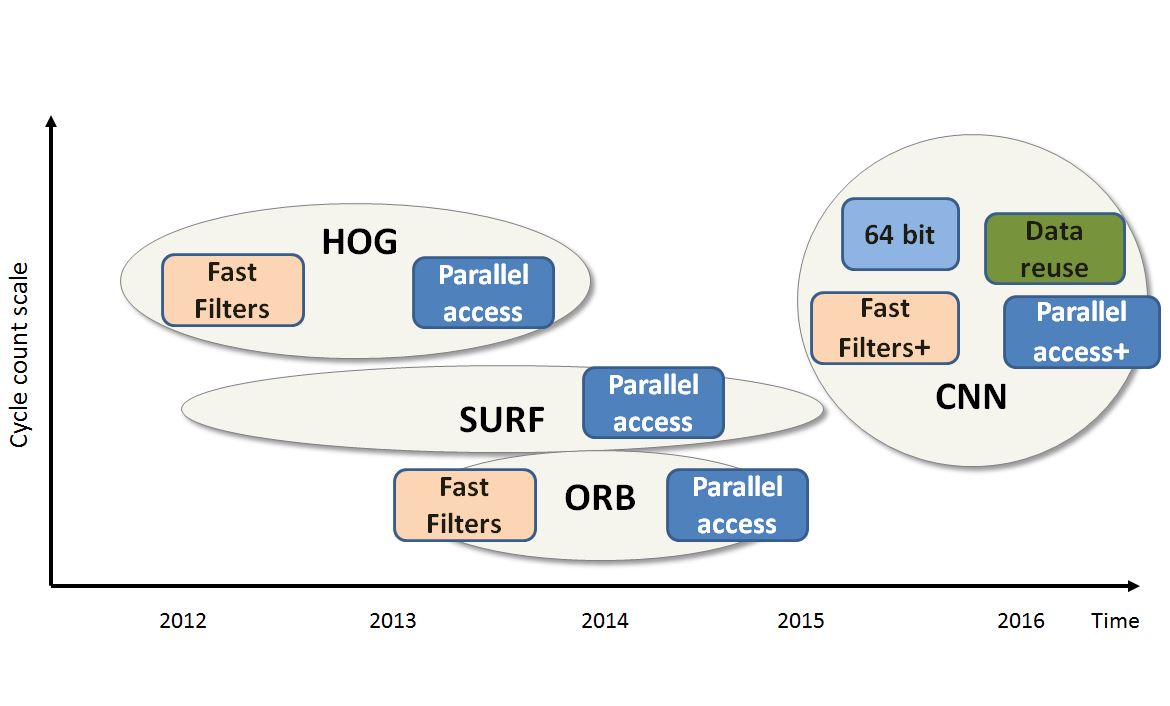
Computationally Efficient Algorithms Like SURF and ORB are Giving Way to More Powerful Frameworks such as CNN
CNN: The Next Frontier for Object Recognition in Embedded Platforms
The advent of intelligent vision features in camera-ready smartphones, tablets, wearables, surveillance and automotive systems is taking the industry to a similar crossroad where more advanced algorithms are required for computationally intense applications which provide a more ambient and context-aware user experience. So, once more, there is a need to reduce the computational complexity to overcome the brute force nature of powerful algorithms used in these mobile and embedded devices.
Inevitably, the need for higher accuracy and more flexible algorithms are leading to vector accelerated deep learning algorithms like Convolutional Neural Networks (CNN) which are used for classification, localization and detection of objects in images. Take a use case like traffic sign recognition, for instance, CNN based algorithm will outperform in accuracy of identification all of today’s object detection algorithms. In addition to the high quality of CNN, the main advantage over traditional object detection algorithms is that CNN is very adaptive. It enables quick tuning to new objects without changing the algorithm code. Hence, CNN and other deep learning algorithms seem to be set to dominate object detection methods in the near future.
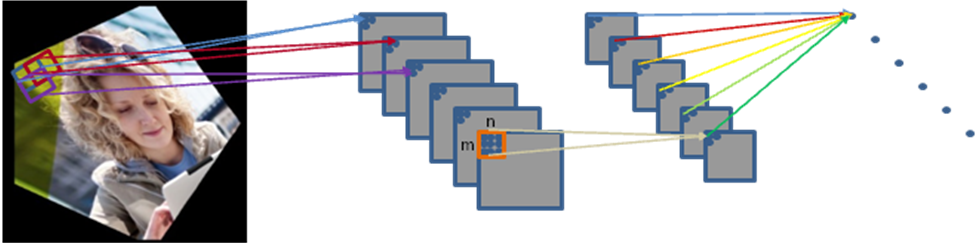
The final pooling layer in CNN
CNN imposes very heavy computational requirements on mobile and embedded devices. Convolution is the main part of the CNN computations. The 2D convolution layer in CNN allows users to utilize the overlapping convolutions for efficient processing by executing one or several filters in parallel on the same input. So, for an embedded platform, designers should be able to perform convolutions very efficiently to make the best of the CNN flow.
In fact, CNN isn’t exactly an algorithm, but more of an implementation framework that allows users to optimize basic building blocks and create an efficient neural network detection application. And it requires more computational effort as CNN framework is performed on the pixel-by-pixel level, and the calculation per pixel is a highly demanding operation..
Making Case for Vision Processor
We at CEVA have figured out two other venues for improving computational efficiency while working on upcoming algorithms such as CNN. First, a parallel random memory access mechanism which can enable a multi-scalar feature and allows vector processors to manage parallel load capabilities. Second, sliding window mechanism can improve data utilization and prevent same data to be reloaded several times. Third, a 2-dimension data processing mechanism, improves data utilization and prevents same data to be reloaded several times. There is a large data overlap in most imaging filters and convolutions on large input frames. This data overlap, which increases with the processor vector size, can be used to reduce the data traffic between the processor and the memory and reduce the power consumption accordingly. This mechanism—making use of large data overlaps—allows developers with a freedom in implementing efficient convolutions in deep learning algorithms and in general enables very high utilization factors of the DSP MAC operations.
Deep learning algorithms for object recognition are raising the computational bar once more, and that requires a new class of intelligent vision processors that can augment the processing efficiency and accuracy to meet the challenge. The CEVA-XM4– CEVA’s most recent vision and imaging platform- builds on the combination of vision algorithm expertise and core architecture know-how and provides a well-tuned vision processor to meet the challenges of embedded computer vision.
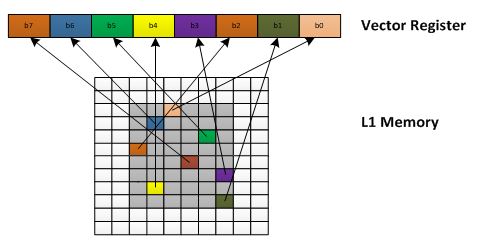
CEVA-XM4 Parallel random memory access mechanism which enables vectorizing scalar code
- Read the article on Design and Reuse
- Download the presentation
- Download CEVA-XM4 white paper
You might also like



More from Deep Learning

Bringing Power Efficiency to TinyML, ML-DSP and Deep Learning Workloads
In recent times, the need for real-time decision making, reduced data throughput, and privacy concerns, has moved a substantial portion …

Human Presence Detection and You
Mobile phones and tablets are getting more powerful, but if you’re serious about doing work (remotely), the dedicated work laptop …

Meeting the challenges of edge AI
AI is becoming an increasingly popular technology, finding uses in more and more applications in sectors such as automotive, vision …