













Imagine you’re at the airport calling a friend. There are conversations going on all around you, planes taking off/landing, dozens of suitcases rolling across the tile floor, and probably a few babies crying. Your friend is on the other end, in a busy restaurant. They have their own ambient noises to contend with, the clatter of utensils and plates, the buzz of conversation, music in the background, and probably a few babies crying. Instead of loud, muddled sound, the conversation is calm and clear on both ends.
This is all thanks to noise suppression and active noise cancellation (ANC). These two features are commonplace with audio products these days, but they’re not just buzzwords. These technologies help mitigate the impact of noise in different but important ways. This post will explain the difference while taking a deeper dive into the noise suppression aspect of it.
Noise Suppression
Let’s look at the first part of the equation, you are speaking into the microphone in a loud environment.
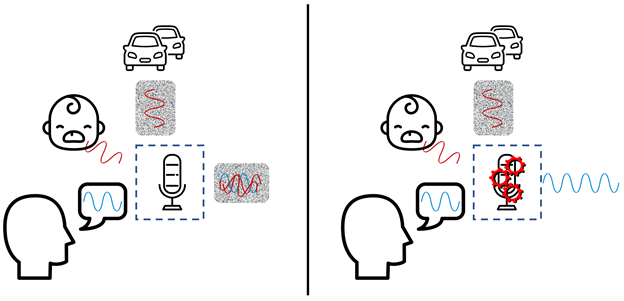
In this example, there’s a consistent background noise from the cars. This is what’s referred to as stationary noise – a repeatable pattern that isn’t the voice we’re looking for. Air conditioning, airplanes, car engines, and fans are all examples of stationary noise. A baby crying, however, is not a consistent sound, and is appropriately named non-stationary noise. Other examples are a husky howling, an active drill or hammer, keyboard clicks, or the clinking of silverware in a restaurant. These noises come and go very quickly.
Both types of noise can be captured by the microphone(s) and, without any processing, produce an equally noisy output over your intended message. This is shown in the left part of the diagram. Noise suppression, however, is the processing that removes the background noise to transfer your voice, and your voice alone.
Active Noise Cancellation
Now that your clean voice has transferred through the air to your friend, they still face challenges in hearing clearly. This is where active noise cancellation comes in.
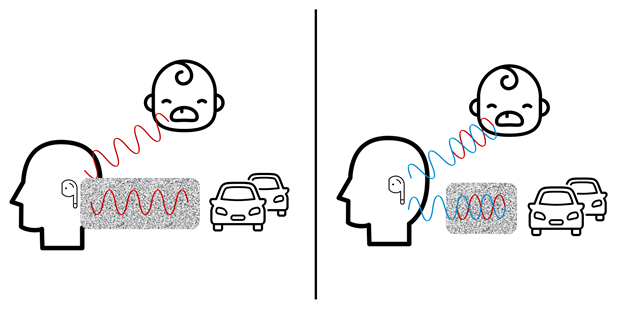
Like before, there are stationary and non-stationary noises that affect what comes in through the earbud. Unlike earlier where noise is processed out, active noise cancellation aims to mitigate external noise by cancelling them out entirely. Microphones capture incoming sound and create an inverse signal of the unwanted noise and play it to neutralize the soundwaves as best as possible. At a high level, it’s conceptually like summing +5 and -5 number to get to 0.
This general principle of active noise cancellation can be used in two main ways with hardware. There is feedforward ANC, which uses a microphone on the outside of the hearable, and feedback ANC, which uses a microphone inside of the hearable, closer to the ear.
Feedforward ANC is more sensitive to noise by virtue of being outside of the ear. It can pick up noise clearly as it comes towards the hearable. It can then process this and output its phase cancelled signal. This gives it the capability to isolate specific sounds, especially those in the mid-frequency range. This includes the stationary sounds we mentioned earlier in the post, but also speech. However, by being on the outside of the device, feedforward ANC is more easily affected by external noise, like wind or your earbud consistently rubbing on the side of your hoodie (definitely not an example by experience).
Feedback ANC isn’t affected by uncooperative hoodies by virtue of it being inside the hearable and makes it resistant to other sorts of incidental interference. This sheltering of sound is great, but higher frequency sounds that make it through the headphones are less likely to be cancelled. Similarly, the internal feedback microphone will need to differentiate between the played music and noise. And since it’s feedback (eh eh?) is closer to the ear, it also needs to process this information faster to maintain the same latency as you would from a feedforward setup.
Lastly, there’s a hybrid active noise cancellation which – you guessed it – combines both feedforward and feedback ANC to create the best of both worlds at the cost of power and hardware.
A Deep Dive into Noise Suppression
With an understanding of the fundamental difference between noise suppression (suppressing talker ambient noise for the far end listener) and active noise cancellation (cancelling listener own ambient noise for himself), let’s focus on how noise suppression can be accomplished.
One method uses multiple microphones to suppress data. By collecting data from multiple locations, the device acquires similar (but still different) signals. The one closer to the mouth receives a noticeably stronger voice signal than the secondary microphone. Both microphones receive a similar strength of signal of the non-voice background. By subtracting the secondary microphone sound from the stronger voice microphone, you’re left with mostly voice information. The further spaced the microphones are, the easier it is to suppress with this simple algorithm as the signal difference between the closer and further microphone will be greater. However, this method is less effective when you’re not speaking or if the intended voice data changes over time (like if you were walking or running and the phone kept swinging about). Multi-microphone noise suppression is certainly robust, but there’s a drawback of additional hardware and processing.
So what happens if we only have a single microphone? Without the use of additional sound sources for verification/comparing, single microphone solutions rely on an understanding of the noise they are receiveing and filtering it out. This ties back into the stationary and non-stationary noise definitions from before. Stationary noises can be filtered out effectively through DSP algorithms, but the non-stationary noises provide a challenge that can be aided with deep neural networks (DNN).
This method requires a dataset to train the network. This dataset is composed of distinct noises (both non-stationary and stationary) combined with clean speech to create a synthetic noisy speech pattern. This is then fed to a DNN as input with the clean speech as output. This will create a mask or a neural network model which will remove the noise and output only clean speech.
Even with a trained DNN, there are still some challenges and metrics to consider. If this wants to run in real time, with low latency, then you either need a lot or processing power, or a smaller DNN. The more parameters in your DNN, the slower it will run. Audio sampling rate has a similar effect on voice suppression. A higher sampling rate means more parameters for the DNN to churn through, but it nets the higher quality output. For the sake of real-time noise suppression, narrowband voice communication is ideal.
All of this processing is intensive, which the cloud is very good at accomplishing, but that method adds significant latency. Considering that humans can reliably detect latency over ~108 ms, the latency added over the cloud is not ideal. However, running a DNN on the edge requires some smart tweaking. CEVA has been focused on perfecting our capabilities in sound and voice. This includes field verified voice clarity and command recognition algorithms that deliver clear communication and voice control, even at the edge. Contact us to hear for yourself.
You might also like

More from Audio / Voice

LE Audio and Auracast Aim to Personalize the Audio Experience
We live in a noisy world. At an airport trying to hear flight update announcements through the background clamor, in …

Evaluating Spatial Audio – Part 1 – Criteria & Challenges
We here at Ceva, have spoken at length about spatial audio before, including this blog post talking about what it …

AI Audio for Voice Enhancement: Deep into the Deep – Part 3
It is Tomer again with more about ENC! Throughout this journey, we've laid the foundation with an introduction and explored …