













AI is becoming an increasingly popular technology, finding uses in more and more applications in sectors such as automotive, vision processing, and telecoms. AI is enabling new capabilities and replacing many conventional algorithms, for example to provide de-noising and image stabilization for smartphone cameras.
But while many AI implementations send data to a cloud data center, this has some major drawbacks: including added latency, privacy risks, and the need for an internet connection.
Instead, designers are looking to create AI systems that run on edge devices, which are often battery-powered – but this raises new challenges to balance the required performance and capabilities against power consumption, particularly as the demand for more computational power continues to grow rapidly.
AI processing challenges
While there are many different edge devices with varying requirements, they basically all aim to maximize performance while reducing power consumption, and minimizing the physical space required. How can design engineers make the right trade-offs to meet these challenges?
With existing AI processors, performance is often limited by bandwidth, and the bottlenecks involved in moving data to and from external memory. This leads to low system utilization, and means the performance/power figure (measured in TOPS/Watt) is restricted.
Another important issue is how to plan ahead for future needs. AI processor chips typically have a long deployment period, and an AI solution must be able to adapt to new requirements in the future, including supporting new neural networks that aren’t yet defined. This means any solution must have sufficient flexibility, and the scalability to grow with increasing performance demands.
AI systems must also be secure, and must meet the highest quality and safety standards, particularly for automotive applications and others where the AI system is potentially involved in life-critical decisions. If a pedestrian steps out in front of an autonomous vehicle, for example, there’s minimal time to respond.
To help overcome these challenges, a comprehensive software toolchain is needed, which also makes implementation simpler for customers and reduces development time.
AI processors step up
Let’s look at how AI solution providers are addressing these challenges, taking vision machine learning as an example.
 Figure 1: NeuPro-M AI processor block diagram, showing memory architecture
Figure 1: NeuPro-M AI processor block diagram, showing memory architecture
Firstly, if we consider the issues of bandwidth-limited performance and memory accesses, these can be addressed with a dynamically-configured two level memory architecture (see Figure 1). This minimizes power consumption due to data transfers to and from external SDRAM. By using local memory resources in a hierarchical manner, this achieves more than 90% utilization, and protects against ‘data starvation’ of the co-processors and accelerators – while also enabling each engine to process independently.
Another way to optimize AI processing is by enabling the processor architecture to support a mixed-precision neural engine. The ability to process data from 2 bits up to 16 bits means less system bandwidth consumption on top of flexibility to run mixed precision networks per use case. Furthermore, bandwidth reduction mechanism like data compression gives the ability to compress the data and weights in real-time, while writing or reading from the external memory. This reduces the memory bandwidth needed, further improving performance and significantly reduces overall power consumption.
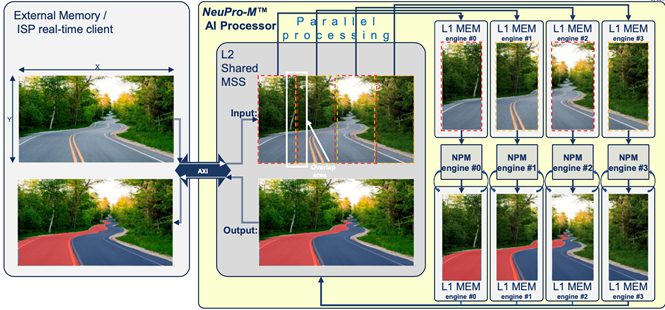
Figure 2: segmentation with quad-engine core
This is the approach taken by CEVA’s NeuPro-M AI processor, which is a self-contained heterogeneous processor architecture for AI/ ML inference workloads. Using this solution as an example, figure 2 shows how a machine vision application could be segmented amongst four AI engines, in this case lane detection on the road ahead. The image data is loaded from external memory or from an external interface, and then split into four tiles, which are each handled by a different engine. Alternatively, the engines might each take on a sub-graph or different task, for example object detection as well as lane identification, to optimize the performance for a specific application.
Each engine has its own on-chip L1 memory, to minimize any bottlenecks or delays. This also means the AI processor can run almost fully independently once it is configured and, in most cases, can run ‘head-to-tail’ “fused” operations pipeline that doesn’t require internal memory access at all, with very little external memory access. This makes it more flexible, and helps improve its power efficiency.
The requirements we discussed at the start of this article also included providing a future-proof, flexible solution. A fully programmable vector processing unit (VPU) that can work in parallel to the coprocessors on the same engine L1 data, can meet this need, by ensuring software-based support of new neural network topologies and advances in AI workloads.
Machine vision optimizations
There are many optimizations that can boost performance in specific AI applications. In vision processing, one such optimization is the Winograd Transform. This is an alternative, efficient way of performing convolutions, such as for a Fourier transform, that uses only half the previously-required number of MACs (multiply and accumulate operations).
For 3×3 convolution layers, the Winograd transform can double the performance achieved, while keeping the same precision as the original convolution method.
Another essential optimization is the use of sparsity, which is the ability to ignore zero in the data or weights. By avoiding multiplication by zero, performance is improved, while preserving accuracy. While some processors require structured data to get the benefits of sparsity, better results can be achieved with a processor that provides full support for unstructured sparsity.
Typically, an AI system would need to hand some of these optimization functions or network inherent operations, such as Winograd transforms, sparsity mechanisms or pulling, self-attention operations & scaling, to specialized engines. This means that data needs to be offloaded, and then loaded back after processing – which adds latency and reduces performance. Instead, a better alternative is to connect accelerators directly to engine local shared L1 memory or better-off in most cases, conduct fused operations meaning on-the-fly end to end pipeline processing from one coprocessor to another, without the need to access any memory during execution.
How significant are these optimizations? Figure 3 shows the performance improvements achieved by a single engine NPM11 core, compared to CEVA’s previous generation of AI processor, for a typical ResNet50 implementation. You can see that the basic, native operation achieves a performance boost of nearly five times.
Adding a Winograd transform and then sparsity engine takes this performance increase further, up to 9.3 times the previous generation process. Finally, using mixed precision (8×8 & low-resolution 4×4) weights & activations for some of the network layers gives a further increase with negligible accuracy loss – achieving nearly 15 times faster performance than the previous processor, as well as a 2.9x increase over the native implementation.
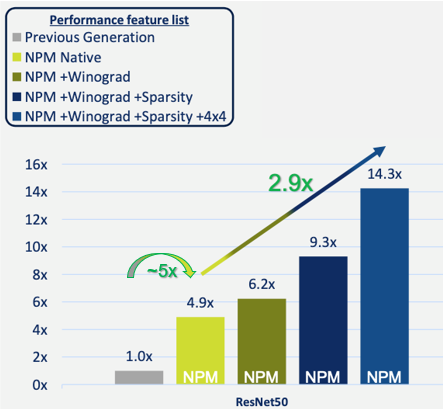
Figure 3: NPM11 (single engine core) performance improvements
Conclusion
We’ve seen how a new memory architecture and local ‘load balancing’ control implementation (pipeline processing vs. consecutive processing of the same data), minimizes external accesses and utilizing hardware to the full, can improve performance without requiring more power, and how optimizations such as Winograd transforms and sparsity can give a further boost.
Overall, a modern AI processor can provide a fully programmable hardware/software development environment, with the performance, power efficiency and flexibility needed for demanding edge AI applications. This enables design engineers to benefit from effective AI implementations within their systems, without increasing power consumption beyond the budget of their portable edge devices.
Published on Electronics Weekly (pg 20-21)
You might also like


More from Deep Learning

Bringing Power Efficiency to TinyML, ML-DSP and Deep Learning Workloads
In recent times, the need for real-time decision making, reduced data throughput, and privacy concerns, has moved a substantial portion …

Human Presence Detection and You
Mobile phones and tablets are getting more powerful, but if you’re serious about doing work (remotely), the dedicated work laptop …

Optimizing AI for embedded applications
In my previous blog I talked about how demand for AI-based interfaces has become almost unavoidable—and that adding an AI-based interface …