













In part 1, we discussed some important concepts related to sound processing and environmental noise cancellation that are essential to keep in mind when designing an ENC (Environmental Noise Cancellation) system. Now, let’s talk about the rest of the equation, which is the noise itself. In this section, we will characterize common noise types and explore some of the classical speech enhancement methods that are commonly used to tackle this problem.
Researchers typically categorize noises as either stationary or non-stationary, depending on different characteristics. Understanding the differences between these two types of noise can provide valuable insights into their properties and ways to deal with them.
Stationary noise refers to noise that remains relatively constant in its statistical properties over time. In other words, its statistical characteristics such as mean, variance, and autocorrelation remain constant or change only slightly over time. Common examples of stationary noise include the hum of an air conditioner or the constant hum of a refrigerator. Stationary noise can often be easily characterized and analyzed using mathematical techniques, making it suitable for various analytical algorithms to predict and cancel.
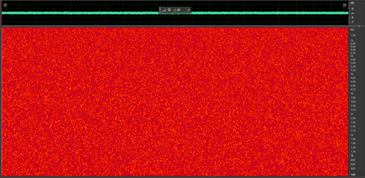
(a)
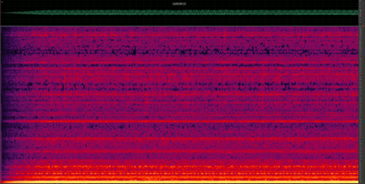
(b)
Figure 1: Spectrograms of stationary noise samples. (a) white noise (b) refrigerator hum noise

One famous example of stationary noise is “white noise.” It’s a random noise that contains all frequencies of the spectrum in equal intensity. It’s called “white” noise because it’s similar to white light, which contains all visible wavelengths of light. White noise is often used as background sound to mask other sounds, promote relaxation, or improve sleep. Additionally, it’s used in audio engineering to test and calibrate equipment.
Another example of stationary noise is the hum of a refrigerator. Although it doesn’t have the same intensity for each frequency, we can still predict how it will look in the near future.
Non-stationary noise, on the other hand, refers to noise that changes significantly in its statistical properties over time. This means that its statistical characteristics can vary widely or even abruptly change, making it more complex and challenging to analyze. Non-stationary noise can arise from various sources, such as traffic noise, crowd noise, or other environmental factors. Unlike stationary noise, non-stationary noise poses unique challenges because it requires advanced techniques to capture its dynamic and time-varying nature.
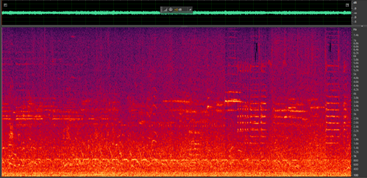
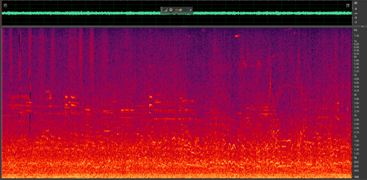
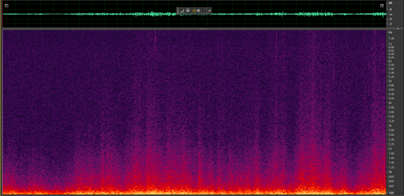
Figure 2: Spectrograms of two different traffic noise samples
Traffic noise is an example of non-stationary noise, which means that its statistical properties change significantly over time. It is a complex and dynamic type of environmental noise that originates from various sources, including spontaneous horns, different engine sounds, and various vehicles passing at different speeds. In addition, the type of road surface, surrounding terrain, and weather conditions can all contribute to varying intensity and frequency content throughout the day. As a result, traffic noise can be challenging to analyze and mitigate because there is no repetitive pattern characterizing this type of noise, making it difficult to predict and learn.
Noises can also be characterized by their duration. Mild, continuous noises such as wind can have a prolonged duration, while impulsive noises (sometimes referred to as transient noise) such as thunder, gunfire, explosions, scratches, and other sudden sounds have a short duration. These impulsive noises can be particularly disturbing because they can occur unexpectedly and do not last long enough for an adaptive speech enhancement system to learn and cancel them.
Noises can also be differentiated by their energy distribution over the spectrum. For example, in wind noise, most of the energy is concentrated in the lower frequencies (<500Hz), while in bird chirps, most of the energy is between ~3kHz-7kHz. This difference in energy distribution can have a significant impact on the perception and analysis of different sounds. Understanding the energy distribution of different sounds can help in developing effective noise reduction and filtering techniques to improve the quality of audio signals.
(a)
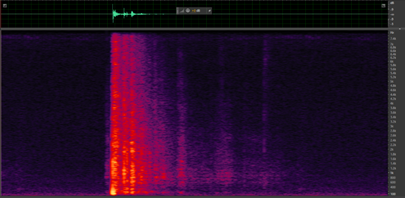
(b)

(c)
Figure 3: Spectrograms of (a) wind noise (b) gunfire (c) birds chirp
One particularly challenging scenario in speech enhancement is known as “The Cocktail Party” problem. This problem refers to the difficulty of separating and enhancing a target speech signal from a mixture of multiple speech signals or other interfering sounds in a noisy environment, much like trying to focus on a single conversation at a crowded party.
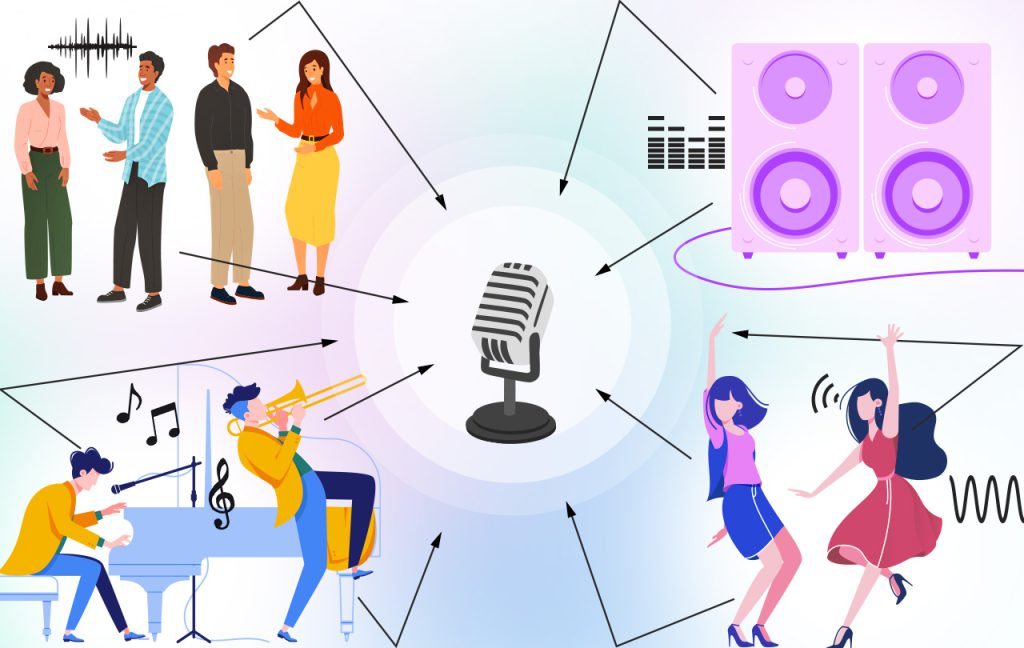
Figure 4: “The Cocktail Party” problem diagram
In real-world scenarios, such as at a cocktail party, a meeting, or a crowded public space, multiple people with varying speech characteristics and unknown sources may be speaking simultaneously. This creates an acoustic mixture of their voices, along with background noise that is also influenced by the room’s acoustics. This results in a challenging scenario where the target speech signal of interest is obscured by the interfering sounds, making it difficult to understand or extract the desired speech signal.
Classic signal processing methods
Many algorithms have been suggested in traditional signal processing theory to deal with the environmental noise cancellation problem. Those algorithms can be generally divided into four main classes[1]:
- Spectral subtractive algorithms: These algorithms estimate/update the noise spectrum when speech is not present and subtract it from the noisy signal. Spectral subtractive algorithms are based on the principle that noise is additive, and they are the simplest enhancement algorithms to implement.
- Statistical-model-based algorithms: These algorithms pose the speech enhancement problem in a statistical estimation framework. Given a set of measurements, corresponding say to the Fourier transform coefficients of the noisy signal, they aim to find a linear (or nonlinear) estimator of the transform coefficients of the clean signal. The Wiener algorithm and minimum mean square error (MMSE) algorithms are examples of statistical-model-based algorithms.
- Subspace algorithms: These algorithms are rooted primarily on linear algebra theory and are based on the principle that the clean signal might be confined to a subspace of the noisy Euclidean space. Subspace algorithms decompose the vector space of the noisy signal into a subspace occupied primarily by the clean signal and a subspace occupied primarily by the noise signal. By nulling the component of the noisy vector residing in the “noise subspace,” they estimate the clean signal.
- Binary mask algorithms: Unlike the algorithms in Classes 1–3, binary mask algorithms make use of binary gain functions. This amounts to selecting a subset of frequency bins (or channels) from the corrupted speech spectra, while discarding the rest. The selection of those bins is done according to a prescribed rule or criterion. Binary mask algorithms have been proven to improve speech intelligibility in some cases.[1] P. C. Loizou, Speech Enhancement: Theory and Practice, Boca Raton, FL, USA:CRC Press, 2013.
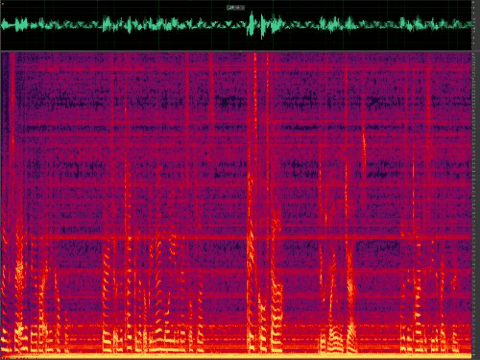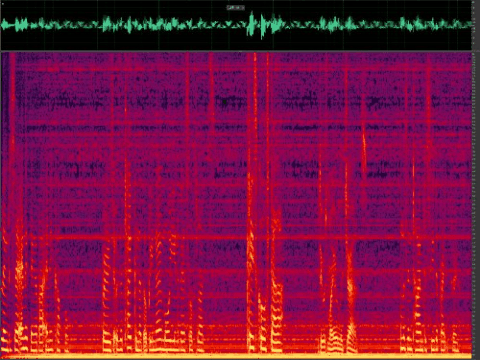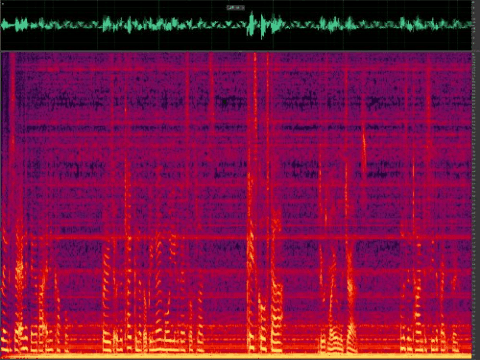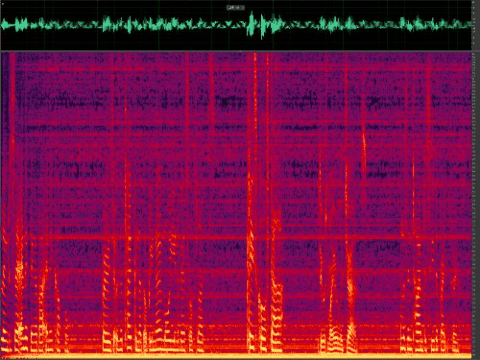
Figure 5: Noise reduction using classic algorithms for speech with refrigerator noise (stationary)
Classical speech enhancement algorithms have been around for decades and have proven to be effective in reducing stationary background noise from speech signals. However, in non-stationary noise environments, their performance often degrades, and they can become computationally complex, leading to significant delays or distortions in the output speech signal. Moreover, these algorithms might require fine-tuning of their parameters to achieve satisfactory results in specific applications, and they may fail to work well in other scenarios altogether. As such, while these classical algorithms can still be useful in certain contexts, newer and more advanced techniques, such as deep learning-based methods, have emerged that can address many of these limitations and achieve superior performance across a wider range of noise conditions.
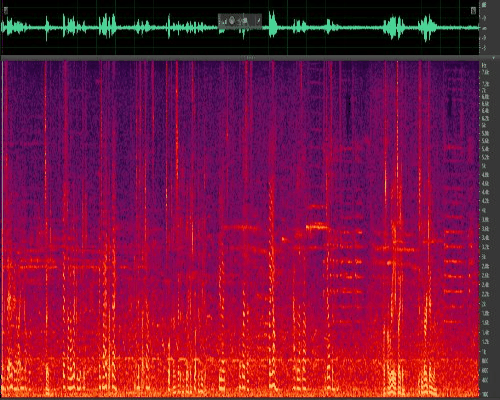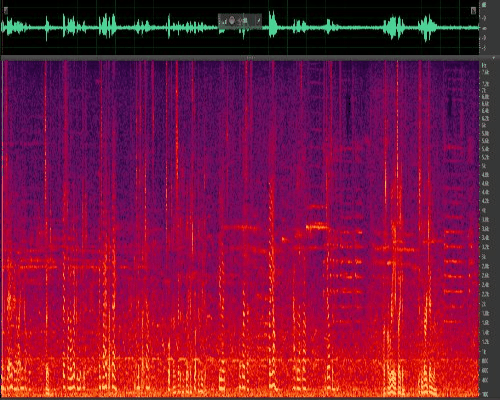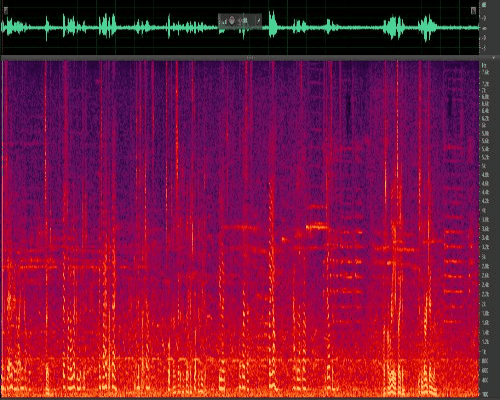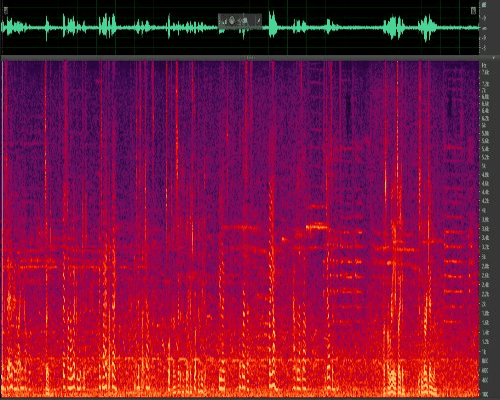
Figure 6: Noise reduction using classic algorithms for speech with traffic noise (non-stationary)
In the upcoming conclusion of our Environmental Noise Cancellation trilogy (part 3), we’ll delve into the cutting-edge technique of using deep learning for ENC. We’ll explore how this method achieves remarkable results and why it’s becoming increasingly popular. Moreover, we’ll explore the robustness of CEVA-ClearVox ENC against different types of noise and provide valuable insights on choosing the optimal voice processing method for your environment and system. So, don’t miss out – join us in the final chapter of this exciting series!
Related blogs:
- Enhancing Audio Quality with Environmental Noise Cancellation in Sound Processing – Part 1 – Introduction
- Noise Suppression vs. Active Noise Cancellation: What’s the Difference?
You might also like



More from Audio / Voice

LE Audio and Auracast Aim to Personalize the Audio Experience
We live in a noisy world. At an airport trying to hear flight update announcements through the background clamor, in …

Evaluating Spatial Audio – Part 1 – Criteria & Challenges
We here at Ceva, have spoken at length about spatial audio before, including this blog post talking about what it …

How Head Tracking Can Elevate Your Spatial Audio Experience
Imagine you are walking down the street, and you hear someone call your name from your right side. You turn …