













Voice-based control is enjoying healthy growth, at $10.7B in 2020 and expected to reach over $27B by 2026. The advantages are self-evident: hands-free operation and a greatly simplified interface. You state directly what you want without having to navigate menus. But as we’ve all experienced, voice can have its own drawbacks. It works fine in a quiet room when you speak directly at and close to the microphone. But on your phone, through wireless earbuds, in a busy supermarket? Not always so well.
AI-based command recognition is important, but even more important is starting with a clear speech signal on which that recognition can operate. Without a clear audio input, your recognizer will often mis-identify commands. Users become frustrated and very quickly stop using the feature.

What Makes Voice Difficult
In a related problem, vision recognition, there’s not a lot of ambiguity in routine images, at least in reasonable lighting. However acoustic detection must contend with a lot more interference. Steady background noise – fans, AC, road noise. And other less predictable background noise – music, conversations, dogs barking, car horns, police sirens. Plucking speech from this acoustic jumble is not so simple. But it is very possible, with the right technology.
This filtering offers advantages beyond speech control. It also improves clarity for phone or conference calls. A listener at the other end of the call will hear you and other speakers more clearly over background noise.
Making this possible is an Audio Front-End (AFE), a set of signal processing stages before recognition or communication. This AFE cleans up raw audio signals, emphasizing the most prominent human speaker over other inputs and reducing audio clutter around that signal.
Voice Activity and Direction of Arrival Detection
Many devices hosting voice-based recognition are battery powered – phones, watches and remotes – and must minimize power consumption. Voice activity detection (VAD) is a very low power stage dedicated solely to detecting a human speaker. Everything else can remain powered down until this detection triggers. How are human voices distinguished from a dog barking or other non-human noises? Through some clever yet very deterministic filtering.
Direction of arrival (DOA) detection requires that the device (phone, remote, etc.) host more than one microphone, often several microphones. Direction of arrival can then be deduced (after human filtering is applied) through slight differences in arrival times of an acoustic pulse at each microphone. DOA detection is important to enable the audio front-end to zoom-in (acoustically) on the speaker, as I’ll explain next.
Noise Reduction
There are multiple ways to reduce noise, some spatially sensitive and some based on single-channel filtering. The spatial methods provide a way to zoom in on a speaker through beamforming. This is the same trick wireless technologies use to preferentially select a certain cell tower over others, but here the trick is applied to acoustic rather than radio waves. Here, signal processing uses inputs from multiple microphones to preferentially optimize reception from a certain direction. Which is guided of course by the DOA detection.
Single channel filtering looks more like conventional filtering in the frequency domain. Most trivially this might be a bandpass filter, though more complex options are also possible. The problem with this approach is that it will often compromise trigger word detection and automatic speech recognition. Some cloud platforms ask that such filters be disabled before using their speech recognition services, for precisely this reason. Single-channel filters can still have value in voice communication rather than recognition, to reduce noise for a listener at the other end of the line.
Echo Cancellation
In any enclosed space (a room, a car cabin), sound travels in many directions and can echo from walls, windows and furniture, arriving a little later at microphones than the direct signal. Or a listener may experience unpleasant feedback from their speaker to microphone. Getting rid of these annoyances, which at minimum add to noise, is the job of acoustic echo cancellation (AEC). AEC techniques compare the reference signal, the first received and strongest signal from the direct path to the microphone, to later received echoes. These are similar in form but attenuated, so are readily understood and subtracted from the signal.
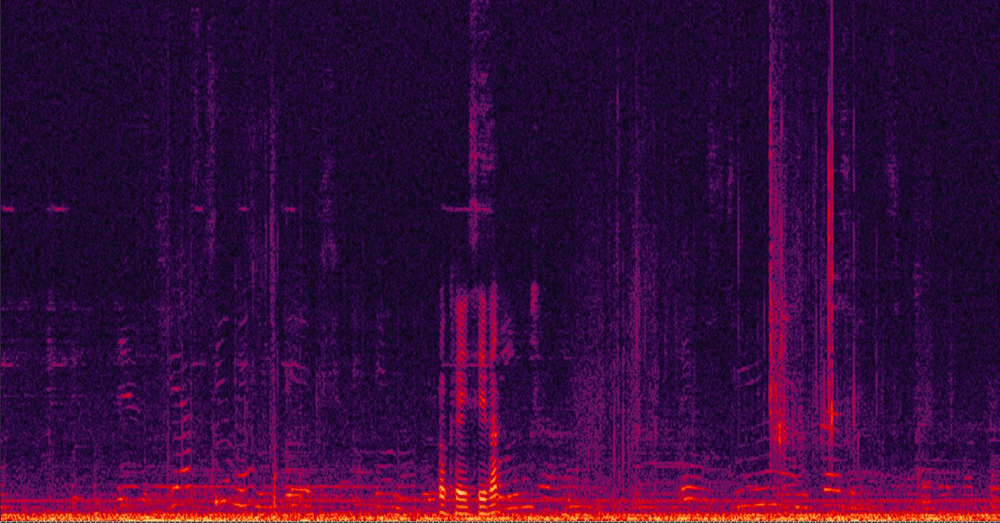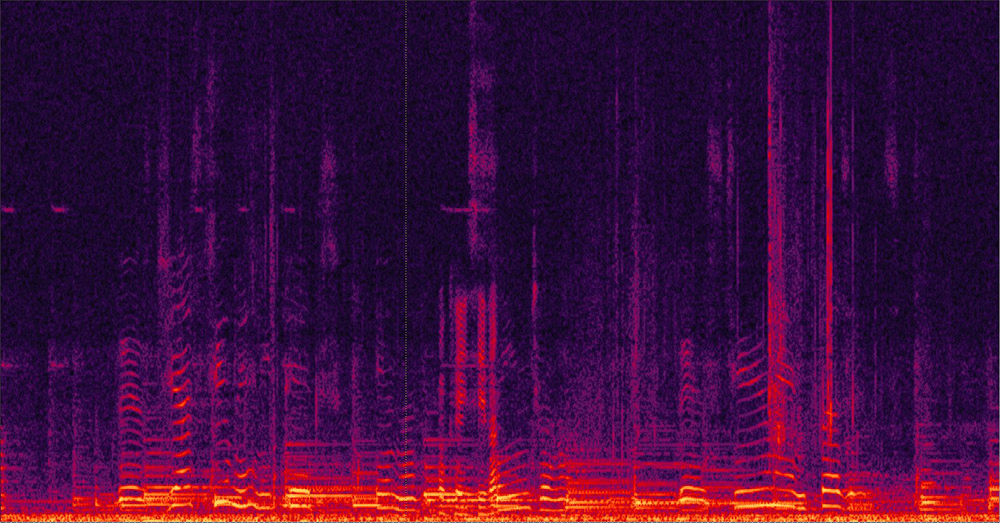
Example for echo cancelation – spectrogram of 2 signals, before and after AEC activation.
Putting It All Together
High accuracy voice recognition is only possible with a high-quality audio front end. That demands some pretty sophisticated audio front-end processing, from human voice activity detection through DOA detection, beamforming, echo cancellation and filtering where appropriate. All based on sophisticated signal processing algorithms. Multiple variations are possible depending on your preferred balance between high-end tech and mass market pricing. I’ll explain more in my next article, and detail how CEVA ClearVox can help you meet both needs.
Published on AudioXpress.
You might also like



More from Audio / Voice

LE Audio and Auracast Aim to Personalize the Audio Experience
We live in a noisy world. At an airport trying to hear flight update announcements through the background clamor, in …

Evaluating Spatial Audio – Part 1 – Criteria & Challenges
We here at Ceva, have spoken at length about spatial audio before, including this blog post talking about what it …

How Head Tracking Can Elevate Your Spatial Audio Experience
Imagine you are walking down the street, and you hear someone call your name from your right side. You turn …