













Recent analyst reports reveal expectations that processing for ADAS system and Infotainment systems will expand significantly over the next five years. They see advances on multiple fronts, not only in AI but also in general compute, and in shifts in how OEMs want to structure electronic content, from edge-based to zonal to central management. A key consideration for any systems builder hoping to benefit from this growth is how to address these diverse auto architecture needs through unified product families.

(Source: CEVA)
ADAS system market opportunity
Yole Développement reports up to 3X growth over the next five years through direct innovation in active safety capabilities and in the digital cockpit, also in advances in adjacent technologies and regulation pushing driver and occupant monitoring systems for example. One question is where this growth is happening – around sensors at the edge, or around central processing in zones, or central processing in the car. Innovation is still prominent at the edge where new entrants can introduce competitive solutions versus slower-moving centralized systems. Conversely, cost, safety and central software control push for more centralization.
From edge processing to central processing
Before ADAS systems appeared, the rapid growth of electronics in cars had driven automotive OEMs to rethink how they wanted to distribute those electronics. Edge sensing has now accelerated that demand. The problem in part was the cost and management of data communication, amplified further by smart sensing – heavy wiring harnesses burning power to transport data from the edge to consolidated processing.
However, sensor fusion must fuse data from multiple sensor perspectives and types and often doesn’t fit well at the edge or centrally. We need edge AI for fast recognition and data reduction, but communication and fusion now push some AI to zonal processors. Meanwhile, as we move to smarter cars with some level of autonomy, those smarts must consolidate distributed inputs under a driving policy manager. This kind of AI cannot be distributed. It must be handled in a central controller, for safety and for a consolidated perspective.
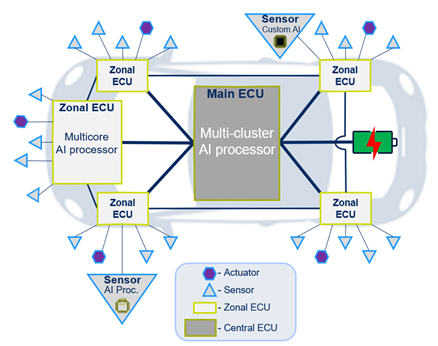
Clearly, three different classes of ADAS system processing are needed – edge, zonal and central – with three different profiles. Edge AI must continue to be fast and low cost (since there will be many of these around the car), a single processor delivering up to 5 TOPS. Zonal processors, consolidating input from multiple edge devices must offer a higher level of parallelism and performance, requiring a higher premium multicore implementation running at up to 20 TOPS. Finally the central driving policy engine must run inferencing against scenario-trained behaviors – and may also need to allow for some level of on-the-fly training. This engine will very likely be a high premium multi-chiplet device, each chiplet a multi-core, supporting up to 200 TOPS or more.
What does scalability imply for ADAS systems?
It is difficult to know yet how revenue opportunities will segment between many low-cost edge devices, fewer but higher premium zonal devices and perhaps only one high premium central device per car. The smart money seems to be on preparing for good opportunities in each segment. Given that, how should SoC product developers architect their solutions?
Training, optimization and infrastructure software represent some of the biggest investments in deploying an ADAS system. Supporting these consistently across a product family then becomes essential to economic success. An edge solution might be tuned for a lighter-weight objective than a zonal or central solution, but it should allow for a dialed-down version of the same core capabilities. So that a common trained network can be compiled, with different compiler options, and inferred into edge, zonal and central solutions.
Correspondingly, the AI hardware platform should allow for scale-up/down. The same architecture, deployable as a single neural engine or multiple parallel engines, with uniform data traffic control and memory hierarchy optimization. Allowing even scale-out to multi-chiplet implementations where needed.
But here’s the real trick. Why should a network developer forgo any of the optimizations they know to increase performance and reduce power, simply because the solution must scale? They should be able to use all state-of-the-art AI methods to meet their objective. Take Winograd transforms, offering 2X performance at reduced power with little to no precision degradation at greatly reduced word widths. These are a popular option in advanced inferencing.
Or take support for a wide range of activation and weight data types available in fully mixed-precision neural MAC arrays. Turning layer precision can significantly reduce memory requirements and power. Sparsity engines take this a step further, eliminating need to multiply by zero values that become even more common in low-precision layers. This increases performance, also reduces power.
Custom operations are a must-have in state-of-the-art accelerators. One way to add these in inferencing is through external accelerators. Another is to be able to perform the calculation in an embedded vector processing unit at the same level as the native engines.
There are more features that next generation network architectures can exploit, like fully connected layers, RNN, transformers, 3D convolution and matrix decomposition.
You would expect all these capabilities to be available for the central, premium engine. Yet you also need scalability in software and network development from that engine to the zonal engine and to an edge engine. You need the same scalable hardware platform, reading the same state of the art trained networks, mapped and suitable scaled to each target objective.
If this sounds like the AI platform you have been looking for, check this out.
Published on Embedded.com.
You might also like


More from Automotive

Challenges in Designing Automotive Radar Systems
Radar is cropping up everywhere in new car designs: sensing around the car to detect hazards and feed into decision …

Buckle Up for More Mandated Driver Assistance
Autonomous vehicles will be a great thing – someday. But governments and regulators don’t want to wait until ‘someday’ to …

Shifting Up to a New Level of Edge AI
The evolutionary phase of technologies is a familiar place, and AI, the prime technology of recent years, is no different. …