













In my previous blog I talked about methods to pick out a clear voice signal from background noise. This is an essential requirement for reliable voice-based control, even for high quality communication from noisy environments. Paradoxically clear voice pickup is easy to solve if you can throw lots of technology at the problem. Just use high-end voice activity detection, many-microphone beamforming and echo cancellation and you’ll have a premium product for high-end markets. A more interesting challenge is to be able to offer almost as good voice pickup quality at more attractive pricing for your mid-range markets. I’ll talk about techniques for both markets here.

(Source: CEVA)
Voice activity detection (VAD)
This step is the start of the voice pickup pipeline – is someone speaking or not, amid the acoustic background? The first step is simply to look at signal, separating out frames with clear activity from background.
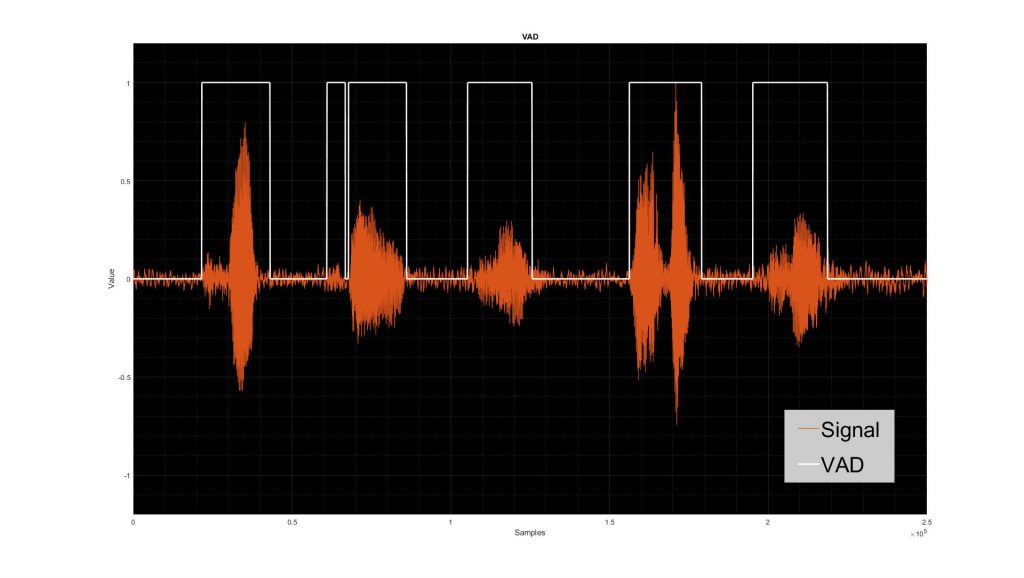
Figure 1: VAD functionality on an example signal.
Looking only at the raw detector signal, some detections will be real and some will be false. Setting a good threshold for SnR can help find a good tradeoff. In a value-priced product a purely energy-based detection (integration in the window) may be enough. A premium product may add adaptive detection using a neural net. Both profiles are common in wearables and earbuds. The common analysis to compare these techniques is to plot true positives versus false positives on a receiver operating characteristics (RoC) curve. This tradeoff between false positive and true positive detections will help you decide how to tune your product.
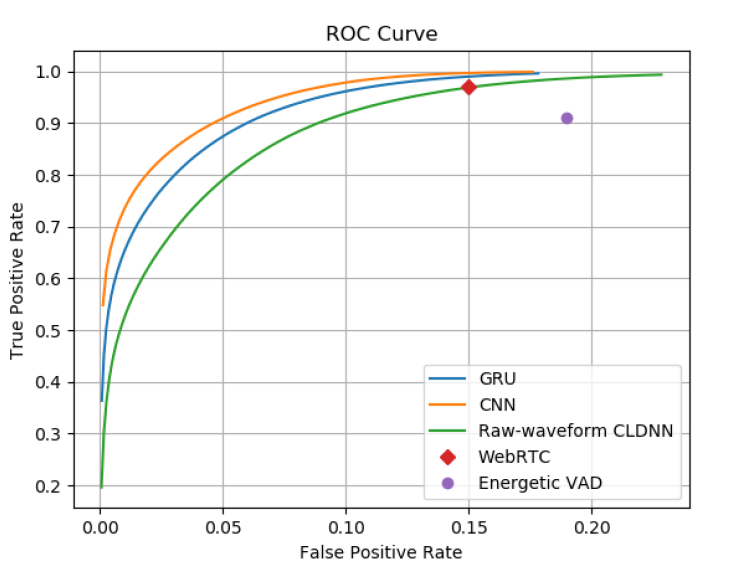
Figure 2: RoC chart of several VAD solutions
Direction of arrival detection (DOA)
This algorithm compares slight delays in arrival time for a detected signal at different microphones. Naturally, pickup for each microphone should be selective to human voice profiles. Then, accuracy of detection will be a function of the number of microphones used and the distribution of those microphones.
High-end devices like smart speakers or smart TVs can generally assume that the speaker is at some distance away, so DOA will be quite accurate. Mid-market products will often be much closer to the speaker and will almost certainly use less microphones, so DOA must be adjusted accordingly. This factor should be considered especially for beamforming, important for noise reduction in the next section.
Noise reduction
Arguably the best possible noise reduction is spatial – zooming into the speaker using beamforming techniques. Which again requires multiple microphones and uses the DOA as a starting point to select where it should zoom in. The more microphones you can use, the more accurately you can zoom in on the speaker, effectively suppressing all other sources of noise. But even with two microphones you can create an improved level of discrimination over one microphone.
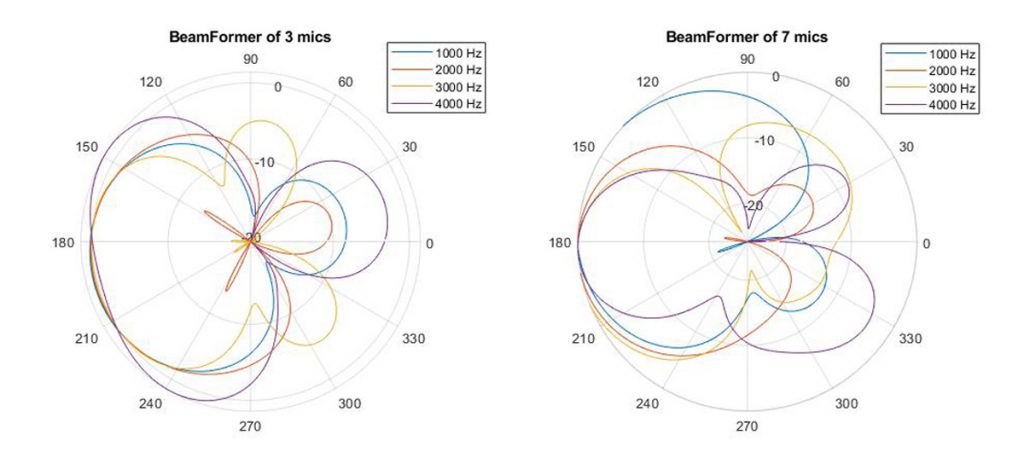
Figure 3: Beamformer filter pattern using 3 mics and 7 mics
For a single microphone, beamforming isn’t possible. This might not be a problem if the speaker is naturally close to the mic. For example, voice pickup in earbuds through bone conduction may already be sufficiently noise free. Also remember that for speech recognition, cloud providers recommend against using filters to remove noise since these can also reduce recognition accuracy.
Echo cancellation
Echoes, mostly from fixed surfaces around a room, create a tail of background noise related to the speaker signal. On low-end devices, the loudspeakers and the plastic capsule of the device tend to add noise or even non-linear effects. Which means that AEC algorithm must be tunable not only to environmental echoes but also to any possible acoustic noise from the device housing.

Figure 4: The standard pipeline for AEC usage
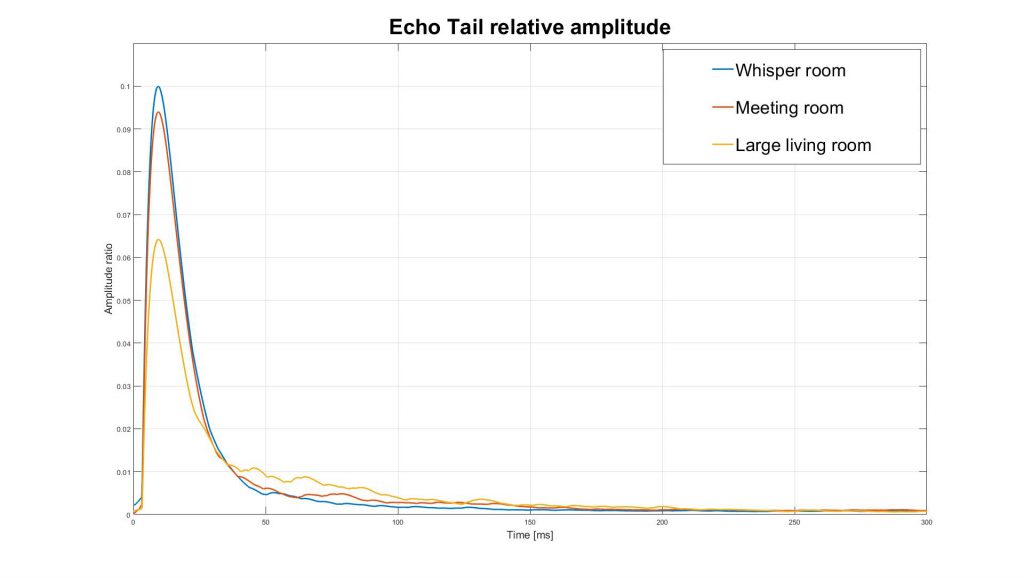
Figure 5: Echo tail amplitude ration over time in 3 different rooms
CEVA ClearVox across the range
As you can see, one size does not fit all when it comes to accurate voice pickup. Solutions must be crafted to meet the needs of different markets, premium versus mass-market objectives. CEVA can help you satisfy both targets, to get maximum value from a high-end implementation with NN-assisted algorithms and many microphones for audio zoom. Or a value-based implementation with energy-based VAD and only two or even one microphone. CEVA has many years of experience in this field. In audio applications for earbuds, headsets and spatial audio. All this experience is encapsulated in our CEVA ClearVox product, available for CEVA DSP and Arm platforms.
Published on AudioXpress.
You might also like



More from Audio / Voice

LE Audio and Auracast Aim to Personalize the Audio Experience
We live in a noisy world. At an airport trying to hear flight update announcements through the background clamor, in …

Evaluating Spatial Audio – Part 1 – Criteria & Challenges
We here at Ceva, have spoken at length about spatial audio before, including this blog post talking about what it …

How Head Tracking Can Elevate Your Spatial Audio Experience
Imagine you are walking down the street, and you hear someone call your name from your right side. You turn …