


Industry’s Most Comprehensive 5G Baseband Platform IP for Mobile Broadband and IoT
Ceva-PentaG2 is Ceva’s second generation 5G NR baseband modem IP platform. It is the industry’s only...
Overview
The Ceva-XC12 is the first DSP architecture that offers the raw performance and power efficiency required for multi-gigabit class modems. This flexible architecture with multiple options enables it to be customized, configured, and scaled to address applications such as smartphones and other terminals, advanced and centralized access points, small cells, macro cells and cloud RAN (C-RAN).
Ceva-XC12 supports:
- 5G use cases
- LTE-Advanced Pro Evolution
- enhanced Mobile Broadband (eMBB)
- Licensed Assisted Access (LAA)
- MulteFire carrier aggregation
- LTE/Wi-Fi Aggregation(LWA)
- cellular V2X
- Wi-Fi 802.11ax
- WiGig 802.11ad
- Fixed Wireless Access (FWA)
- Virtual Reality (VR) systems
Ceva-XC12 is underpinned by a host of technology advances, including a new micro-architecture to meet high frequency requirements and ultra-low power consumption. The Ceva-XC12 can operate at 1.2 GHz in 16 nm while using 50% less power than its predecessor, the Ceva-XC4500. Massive computation capabilities enable it to maintain a high bit rate via the use of quad-vector processor units (VPU).
Unique high-precision arithmetic achieves optimal resolution with up to 256×256 dimension matrix processing. Specialized instructions boost all baseband processing components, and new core streaming interfaces facilitate ultra-low latency transfers between cores or accelerators. A control plane for massive-user management and for multi-RAT (Radio Access Technology) systems incorporates a Scalar Processing Unit (SPU) with a CoreMark/MHz score of 4.3, and is designed to handle the huge number of users required for LTE MTC and 5G IoT.
Benefits
Designed to meet the demanding requirements of extreme multi-gigabit communications use cases
Scalable architecture addresses the full range of eNodeB and gNodeB, ranging from femtocell, small cell, macrocell RRH to Cloud RAN
Delivers up to 8X more performance and consumes 50% less power than its predecessor
Quad-vector processor addresses the needs of next-generation wireless applications
Main Features
- Core features:
- Fully programmable DSP architecture incorporating unique mix of VLIW and SIMD vector capabilities
- 14-stage pipeline enables very high speed for the most extreme use cases
- 8-way VLIW provides optimal hardware utilization
- Extremely powerful vector processor supports fixed- and floating-point operations with 128 MACs per cycle
- Unique high-precision arithmetic – up to 256x256 dimension matrix processing and non-linear operators
- Fully redesigned CPU/DSP SPU with optimizing C compiler for protocol, control, and DSP native C code supports very low overhead RTOS multi-tasking with dynamic branch prediction.
- Massive number of IoT/MTC users served by control plane
- System features:
- Core streaming interfaces support ultra-low latency
- AMBA 4 compliant matrix interconnect
- Comprehensive multicore support with ACE-compliant cache coherency
- Hardware/software partitioning delivers exceptional power efficiency while maintaining software flexibility with Queue and Buffer Managers and auxiliary AXI ports
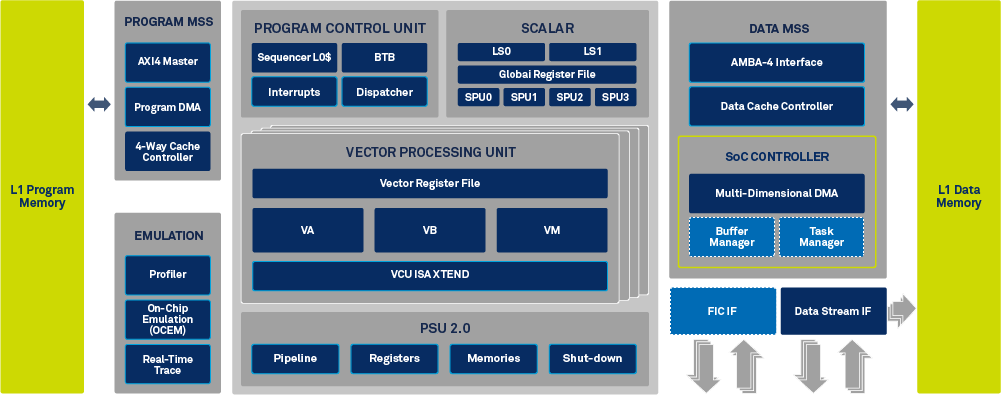
Block Diagram
5G NR base-stations redefine the SDR paradigm
How CEVA-XC12 solves the daunting computing and latency challenges of 5G NR