













Voice-activated virtual assistants have been spreading like wildfire. Apple’s Siri, Amazon’s Alexa, Google Home, Microsoft’s Cortana, and many others are competing to lend us a helping hand. Let’s take a look at what’s fueling this fire, what challenges stand in its way, and what concerns it brings to light.

Evolving from speech recognition to speech understanding
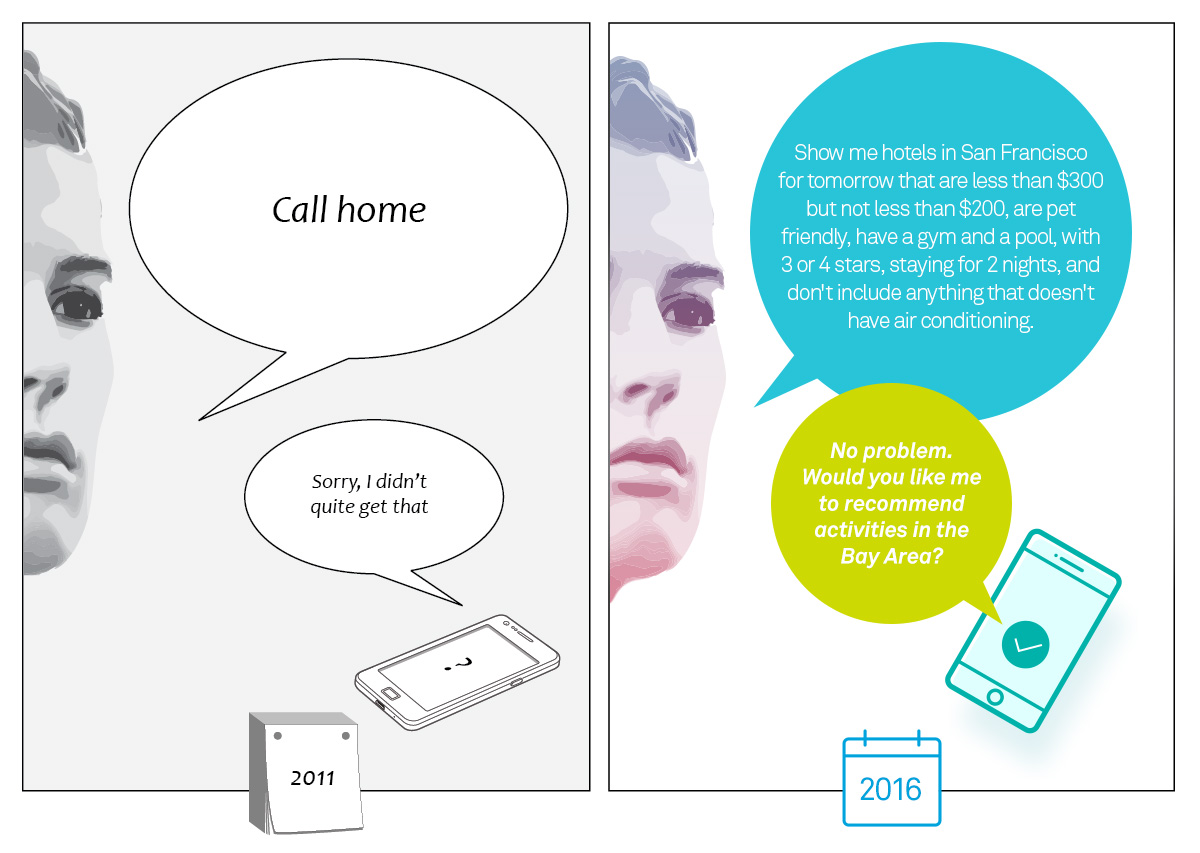
Just a few years ago, speech recognition was a huge challenge, and one of the most coveted hands-free user interfaces. I can easily recall how the first versions of Siri misheard what I said, or repeatedly responded “Sorry, I didn’t quite get that”. Today, significant advances in machine learning, spurred by cheaper and more efficient processing power, have made speech recognition so ubiquitous, that it’s practically taken for granted. In a recent keynote, Google Senior Fellow Jeff Dean claimed that neural networks reduced word errors by 30% when applied to speech recognition. Alongside direct improvements in speech recognition, noise cancellation and speech enhancement has also benefitted significantly from neural networks. An excellent example of this is Cypher’s technology, which isolates voice using deep neural networks. ASR targeted noise cancellation improves the raw data for the speech recognition engine, making the task more likely to succeed. These factors have led to the current state, in which speech recognition is a reliable, useful interface on many devices.
As a result, the industry has shifted to tackling the next big challenge: understanding the full richness of spoken language, including complex, compound sentences and contextual references. More simply put, machines are gradually acquiring the ability to carry on a conversation. According to Houndify, a company specializing in speech understanding, you can ask their conversational interface a query such as: “show me hotels in San Francisco for tomorrow that are less than $300 but not less than $200, are pet friendly, have a gym and a pool, with 3 or 4 stars, staying for 2 nights, and don’t include anything that doesn’t have air conditioning.” In addition to complex queries, they claim that their platform also supports context and follow-up, making the interaction similar to the way we normally speak. This level of complexity was in the realm of science fiction less than a decade ago. These efforts to achieve full speech understanding are also gaining momentum from the open source community, after almost all the big players in the industry released their machine learning frameworks on various platforms.
The engine behind this accelerated evolution is the huge leap forward in Artificial Intelligence driven by machine learning in recent years. In tandem with the advances in software, the hardware is also steadily improving, making computation more powerful and efficient. An example of this simultaneous progress is Google’s Tensor Processing Units (TPU). These are Google’s internally developed accelerator chips, used to power their machine learning projects, like AlphaGo. Tailoring the hardware to suit the needs of their deep neural network algorithms gives them a significant edge over the competition.
When dealing with connected mobile devices, power and response time constraints are even more crucial. Limitations on size, weight, and battery life make the challenge greater, but this will undoubtedly be overcome in time. Bringing the advantages of intelligence to low-power, portable devices is the next obvious step in this evolution. Achieving this requires attention to every milliwatt, and every clock cycle to achieve the desired efficiency.
Conversational Assistants in the Home Arena
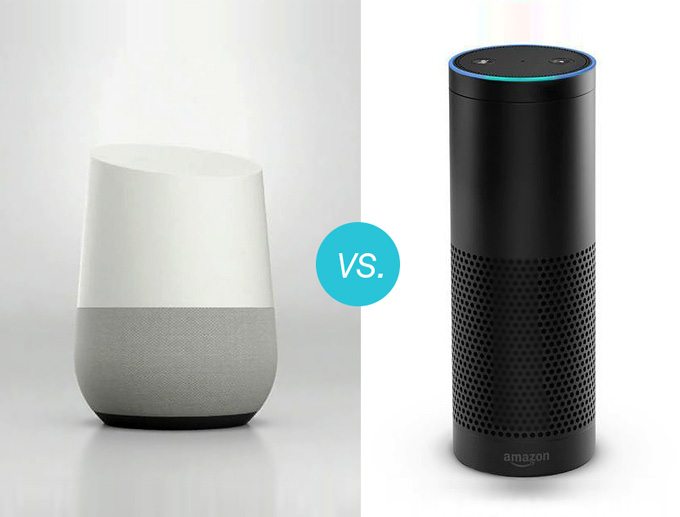
In the smarthome use case, Amazon started the trend with the Echo, which introduced their conversational assistant, Alexa, into millions of homes. The successful, always-listening wireless speaker started out mainly as a 7-microphone, far-field voice activated music system with a few cool features. Since then, Alexa has gotten much smarter and handier, with many new features and skills, including ordering pizza and hailing a ride. Amazon also released a portable version called the Echo Tap. The main drawback of the Tap is incorporated in its name – you need to tap it before you speak. A more efficient embedded solution could have supported the same always-listening voice activation as the plugged-in Echo version, and provided a true hands-free interface.
At the recent Google I/O conference, Google announced their version of a smart assistant called Google Home. The unit incorporates the same Google assistant as in the Android powered devices, activated by the ‘OK Google’ phrase. This assistant has already acquired quite a few skills, which you can browse in this nice glossary. During the I/O keynote, Google CEO, Sundar Pichai, claimed that the assistant will continue to evolve to support context, follow-up, and complex sentences, as well, making it fully conversational.
Apple is also gearing up to compete in this strategic market, by their recent decision to open the Siri API to third party developers. This is clearly an important move, as users will gravitate towards the assistant with the richest ecosystem, applications and features. These information age internet giants clearly understand that entering the home is a key access point to consumer’s hearts and wallets …
A truly helpful virtual assistant is always there to offer you all the services of the company behind it. Conversational assistants will not remain tethered to our homes, but will soon be found in many other domains such as automotive, mobile and even inside our ear.
Recording Everything: Privacy Concerns of Conversational Assistants
Most of the processing for all these assistants is done after the raw voice data is uploaded to the cloud. This allows massive servers, with significant computation power, to do the processing. Once uploaded, all the data is recorded and kept by Google, Amazon, or whatever corporation’s service is used. This raises some privacy concerns, to say the least. It basically means that we are nearing a stage where everything we say is recorded and kept by these companies. One possible bypass to this concern is having a strong enough processor to run the software locally, and remove the need to upload the voice data. In this case, the cloud would only be accessed to get information, like the weather, directions, or other services, but not to give information, which could be sensitive and private. On the other hand, the improvements and achievements of machine understanding are an outcome of the collection of big data. To continue learning and improving, the systems will always need more data. Perhaps the solution will come in the form of regulation. It will be interesting to see how this plays out.
Find out more
CEVA is at the forefront of overcoming the challenges of bringing intelligence to even the tiniest devices. Our ultra-low-power CEVA-TeakLite-4 processor is used for a highly efficient always listening/voice wake-up solution, noise reduction, speech recognition, and more – all in an ultra-slim package. This was lately demonstrated in the voice activated Galaxy S7, powered by CEVA, via our customer’s DSP Group chip.
You might also like



More from Audio / Voice

LE Audio and Auracast Aim to Personalize the Audio Experience
We live in a noisy world. At an airport trying to hear flight update announcements through the background clamor, in …

Evaluating Spatial Audio – Part 1 – Criteria & Challenges
We here at Ceva, have spoken at length about spatial audio before, including this blog post talking about what it …

AI Audio for Voice Enhancement: Deep into the Deep – Part 3
It is Tomer again with more about ENC! Throughout this journey, we've laid the foundation with an introduction and explored …