













In two of my previous posts, I discussed deep learning frameworks, features and challenges and the specific challenges of deep learning in embedded systems. In this post, I would like to introduce the toolkit that deals with these challenges and serves as an extremely powerful and effective way to streamline development of deep learning on embedded systems.
The Ceva Deep Neural Network (CDNN) Toolkit is comprised of three key elements:
- CDNN2 Software Framework
- CEVA Network Generator
- CDNN Hardware Accelerators
Together these elements complement the CEVA-XM Family of imaging and vision processors to create a highly power-efficient deep learning solution for any camera-enabled device. This post will take a look at each of these components to see what they do and how they do it.
Supporting Caffe and TensorFlow
CDNN2 is the second generation CEVA Deep Neural Network Software (SW) Framework that is part of the CDNN Toolkit. It supports the most demanding machine learning network topologies, from pre-trained network to embedded system. It enables localized, deep learning-based video analytics on camera devices in real-time. This significantly reduces data bandwidth and storage compared to running such analytics in the cloud, while lowering latency and increasing privacy. Coupled with one of the CEVA-XM intelligent vision processors,, CDNN2 offers significant time-to-market and power advantages for implementing machine learning in embedded systems.
The design of the CDNN2 SW framework is the result of extensive experience with CEVA-XM customers and partners. They have been developing and deploying deep learning systems utilizing our software framework for a broad range of end markets, including smartphones, advanced driver assistance systems (ADAS), surveillance equipment, drones, robots and more.
In addition to support for Caffe, the second generation framework includes support for networks generated by TensorFlow, ensuring that our customers can leverage Google’s powerful deep learning system for their next-generation AI devices. The CDNN2 software library is flexible and modular, capable of supporting either complete CNN implementations or specific layers for a wide breadth of networks. These networks include Alexnet, GoogLeNet, ResidualNet (ResNet), SegNet, VGG (VGG-19, VGG-16, VGG_S) and Network-in-network (NIN), among others. CDNN2 supports the most advanced neural network layers including convolution, deconvolution, pooling, fully connected, softmax, concatenation and upsample, as well as various inception models. All network topologies are supported, including Multiple-Input-Multiple-Output, multiple layers per level, fully convolutional networks, in addition to linear networks (such as Alexnet).
Enabling Developers to Run Network on The CEVA Development Board in Real-time
The CDNN2 flow is comprised of two parts. The first one is the network training stage, which is done offline by our OEM/customers or partners. The training time depends on the network structure, the size of the Image database, and the number of layers that compose the network. The result of the training stage is a trained floating-point network. At this point, we face the challenge of running this network in on an embedded system in an efficient manner. For example, the Alexnet pre-trained network is 253Mbytes floating point Including weights and data.
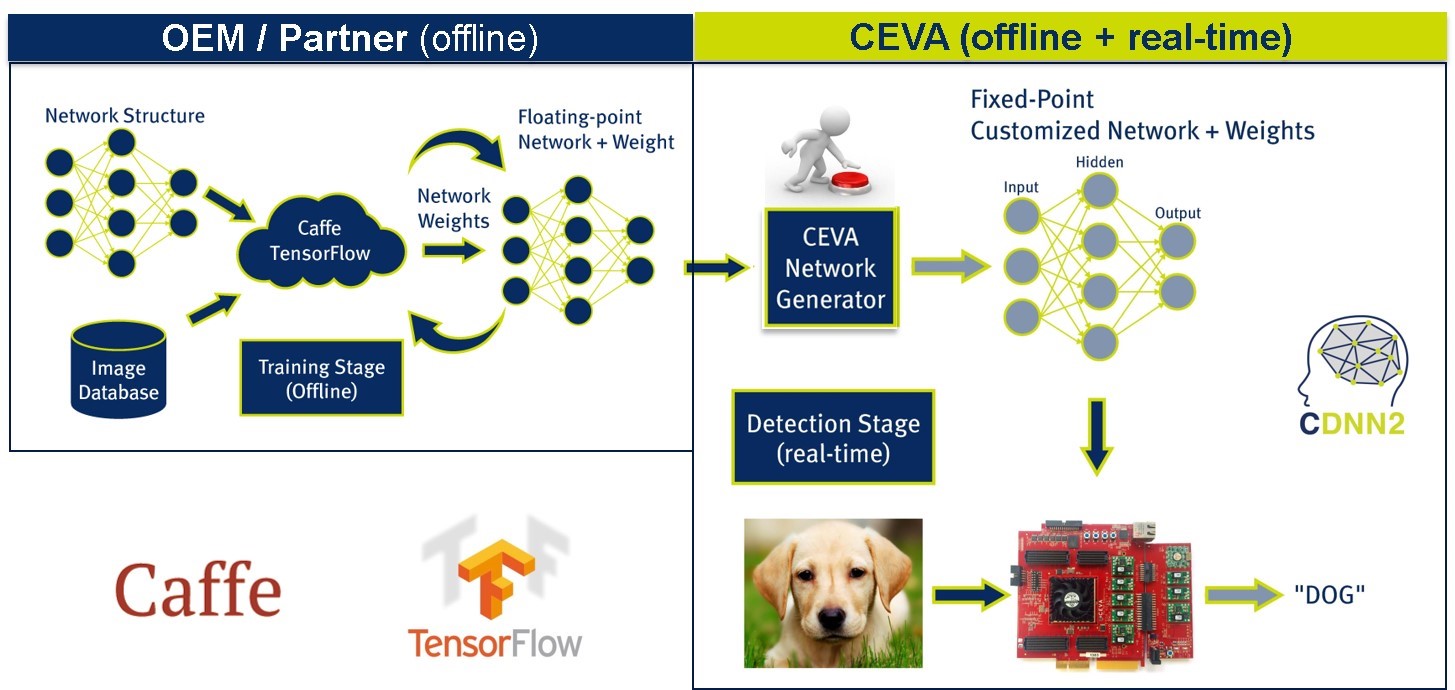
CDNN2 Usage Flow
The second part is where CEVA performs the necessary conversions and makes the network embedded-ready. A key component within the CDNN2 framework is the offline CEVA Network Generator, which converts the pre-trained neural network to an equivalent embedded-optimized network in fixed-point math at the push of a button. CDNN2 deliverables include a hardware-based development kit, which enables developers to not only run their network in simulation, but also to run it with ease on the CEVA development board in real-time.
Real-Time CDNN2 Application Flow
The application flow starts with a real-life scene, which is handled by the application’s pre-processing stage. The preprocessing includes scaling, background reduction and region of interest (ROI) selection. This stage can be executed on both the host side and the DSP side. The pre-processing stage sends the selected ROI to the CDNN real-time library for processing. This uses the CNN application API.
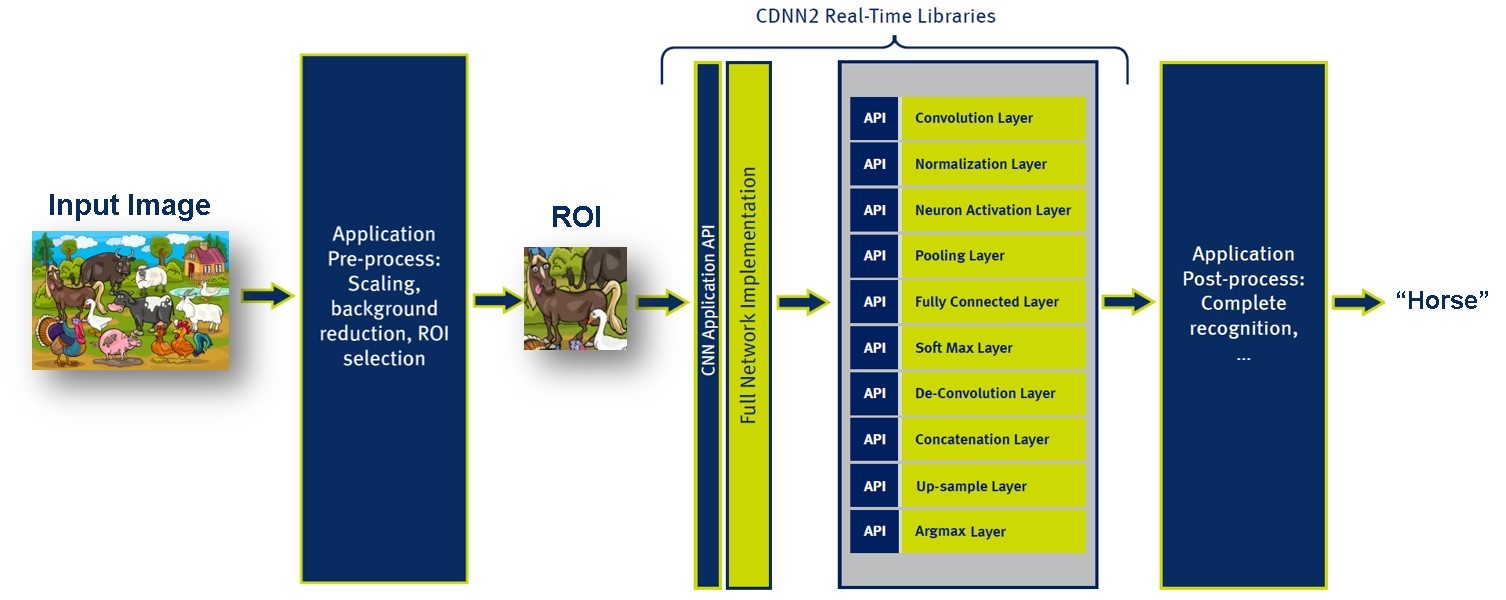
CDNN2 Application Flow
As you can see in the above image, CEVA provides API for each one of the layers, which provides full flexibility. The output from the CDNN real-time library is the ROI classification. Next, the application post-processing block completes the recognition phase, and continues to track new objects that were not recognized.
AlexNet – Network Performance
To demonstrate the efficacy of this approach on a real neural network, let’s take a look at Alexnet. This is a network that includes 24 layers and can recognize 1000 classes. The required memory bandwidth of the pre-trained network is about 250 Megabytes floating point. This includes both the weights and the data. In terms of embedded systems, this is a very heavy network, and running it poses a significant challenge. In the case of CEVA solution, after using “CEVA offline Network Generator” together with the real-time CDNN library, the bandwidth is optimized to 16 Megabytes fixed-point. This is already optimized for CEVA-XM vision processor architecture.
CEVA Network Generator – Embedded Ready in Less than 10 Minutes
As mentioned before, the CEVA Network Generator is a key component in the CDNN solution. The main value of this component is the ease-of-use and the time it saves in porting, converting and adapting the network to an embedded platform. This is a substantial aspect in determining the development time, the risks that arise in the process and, as a result, the development cost.
So how does it work? As mentioned, the starting point is the image database that is used by Caffe, TensorFlow and other frameworks to train the network offline. The inputs to the CEVA Network generator are files that contain vital data for the conversion process. Here is a detailed look at the input files to the CEVA Network generator:
- caffemodel, which contains the pre-trained floating point network.
- prototxt, which includes the following information about the network structure:
- The SW framework that was used, which can be Caffe or TensorFlow
- The size of the input reference image
- The types of the various layers and their parameters
- Normalization image (if required)
- Labels, which includes the network labeling. The labels define the various options to be communicated to the post processing block later on.
Once all the required parameters to the network generator have been set, the only thing left to do is to “push the button”. The result is a network fully optimized to run the CEVA-XM vision processor. From start to finish, the entire process takes less than 10 minutes. That’s instead of porting the network manually, a task which might require weeks or even months of work. In the following video, you can see a live demonstration of the speed and ease-of-use of the network generator. The entire process of downloading an age classification NN from the internet, passing it through the CEVA Network Generator and running it on the CEVA-XM4 FPGA takes about 7 minutes.
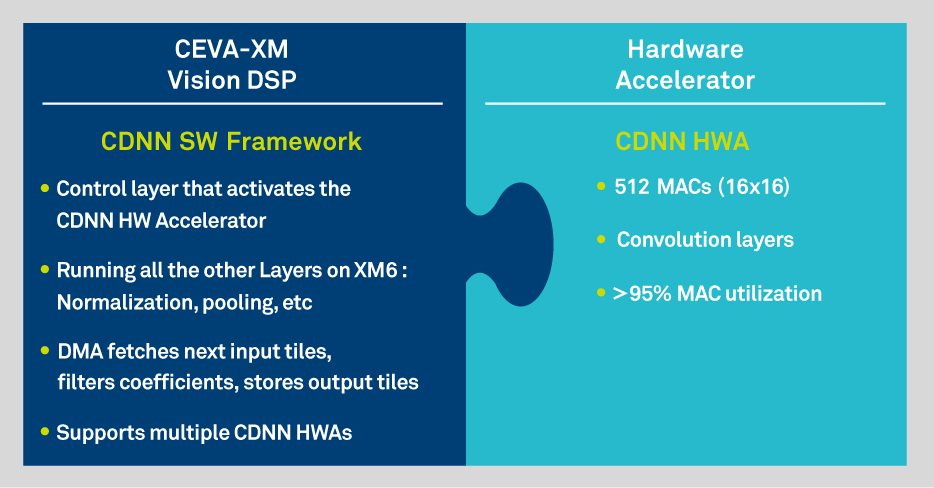
CDNN Hardware Accelerator
In addition to these time-saving software tools, the CDNN toolkit is further enhanced by a powerful dedicated Hardware Accelerator (HWA). The CDNN HWA enables extremely high performance and very low power consumption on deep learning algorithms. Delivering 512 MACs/cycle at 16bit precision, it ensures best-in-class performance to handle today’s most complex neural networks. The CDNN software framework and the CDNN hardware accelerator work in tandem to deliver superior performance while ensuring flexibility to stay up to date with the constantly evolving domain of machine learning.
Artificial Intelligence is Changing the World. It Can Be in Your Embedded System Today
From virtual assistants to autonomous vehicles, Artificial Intelligence (AI) is redefining accessibility of information, convenience, safety and many more aspects of human life. As this intelligence permeates into smaller, portable devices, the possibilities are endless. As I have discussed in depth in this post and previous ones, this raises many challenges. The CDNN toolkit is designed to meet all these challenges, offering the optimal combination of hardware and software IP, augmented by time-saving development tools, paving the way for billions of devices to utilize deep learning. As these technologies develop and evolve, CEVA will continue to be at the forefront of developing Neural Network embedded platforms.
You might also like



More from Automotive

Challenges in Designing Automotive Radar Systems
Radar is cropping up everywhere in new car designs: sensing around the car to detect hazards and feed into decision …
Futureproofing Automotive AI to Manage Lifetime Cost
Cars and trucks are expected to continue their 10– to 20-year lifetimes for the foreseeable future, with corresponding implications for …
Automotive Architectures Push ADAS System Architectures
Recent analyst reports reveal expectations that processing for ADAS system and Infotainment systems will expand significantly over the next five …