Ceva has established a comprehensive partner ecosystem who provide communication solutions, multimedia software, complementary hardware IP, development tools, RTOS, and design services based on Ceva’s industry leading communications and edge AI IP portfolio.
The CEVAnet™ partner program incorporates more than 100 strategic third-party technology partners with innovative complementary software and hardware solutions that can help our customers bring innovative Ceva powered products to market.
Ceva licenses a comprehensive portfolio of communications and scalable smart edge silicon and software IP that helps our customers bring innovative products to market faster, more reliably, efficiently, and economically.
Almalence Incorporated was founded in 2005 by a group of professionals in digital signal processing with an intention of developing and marketing advanced imaging solutions.
Today we are:
Global leader in mobile imaging and computational photography
Developer of cutting-edge image processing technologies, including the only super resolution commercially available for desktop computers and mobile devices
Maker of top super resolution software for DSLR, top mobile camera applications for Android
Mobile imaging solutions vendor to top mobile OEMs in Korea, Japan, China and Taiwan
Licensor of image processing technologies to leading imaging software developers
We are a distributed team of professionals working in USA, Israel, Korea, Russia, China, Taiwan and Japan.
Almalence utilizes CEVA-XM4 and CEVA-XM6 for implementing advanced computational imaging technologies that allow to go beyond the hardware constraints and achieve new levels of imaging systems performance and design. The examples are achieving enhanced low light performance and lossless zoom without increasing the size in mobile, lower z-height and wide aperture mobile cameras without compromising the quality, high resolution and aberration-free VR/AR without enlarging the lens, and ultra-thin optical designs utilizing big DSLR sensors.
ArcSoft Inc., founded by Dr. Michael Deng in 1994 and headquartered in Silicon Valley of California, is a global leader in computational photography and visual computing technologies.
Believing camera and image everywhere, since its founding, ArcSoft has been focusing in the technology and software applications related to imaging and computer vision on main stream devices and platforms, such as smartphones, DSC, VR cameras, drone cameras, IP cameras, smart TVs, robots, smart refrigerators, smart vacuum cleaners, automobile, PCs, tablets, servers, and internet applications.
Normally deeply embedded in customers’ devices, ArcSoft’s software imaging solutions in the past ten years have been shipped with billions of hardware products, helping to improve the capture process, picture/video quality and users experience of mobile photography, enable specific visual features and/or even provide full applications. Customers include Amazon, Asus, Canon, Gionee, Gree, Hitachi, HP, Huawei, Intel, Lenovo, LG, LeTV, Midea, Nikon, Olympus, Panasonic, Qualcomm, Samsung, Sony, Vivo, Xiaomi, and many others.
During its 20 year history, ArcSoft Inc., has successfully built up a top R&D team in the industry with hundreds of scientists and engineers specialized in all aspects related to the technologies of imaging and computer vision. We are actually called by our mobile phone customers the one-stop shopping solution provider on software imaging. More beyond its capability on inventing various advanced imaging algorithms, ArcSoft is also the best and usually the first in the world of enabling or applying complex software algorithms on devices requiring high quality imaging with high performance and low power consumption, but very limited computing resources. These combined capabilities enable our customers offer to the market with innovative features on their existing hardware platform for value differentiations and early time-to-the-market, or with existing features on a cheaper hardware configuration.
Moving forward, by continuously putting over 30% of its revenue back into the R&D, ArcSoft invests heavily in the new visual methodologies and algorithms related to the dual-cameras on mobile phone, mobile 3D modeling, visual deep learning, augmented reality (AR), virtual reality (VR), and imaging artificial intelligence (AI). These efforts will result in more innovative software applications, continuously helping our OEM customers provide the most competitive and high value hardware products to the end users in the future.
Gesture Recognition solutions for mobile and home entertainment devices
Cipia is a leader in Touch Free Interfaces for digital devices. The company was established with the vision to revolutionize the way people interact with digital devices, to create an interaction which is both simple and intuitive.Cipia’s solution is based on advanced image processing and machine vision algorithms, which analyze real time video input from common built-in cameras. This technology is designed for embedded platforms. It is optimized to operate utilizing minimal CPU and power consumption and supports challenging user environments with poor as well as direct lighting conditions.
Cipia’s Technology powers Touch Free UI Solutions which enhance the User Experience while operating devices and applications. These UI solutions enable users to use natural hand gestures to control devices and applications.
CVS is a leading Russian developer focused on computer stereo vision.The company brings in world-class experts to work on innovative machine vision solutions built on the stereo principle. When you drill down to the heart of our hardware and software designed to process images and video, what you find is years of study put in our developers. They’ve dug deeply into pattern recognition, their research run as joint projects between St. Petersburg University’s system programming faculty and Lanit-Tercom.A scientific framework, top-notch professionalism, and a continual hunt for new ideas lets us create breakthrough technology, unique algorithms, and software without peer anywhere else in the world. No matter how complex the job, the team finds the best, smartest, and most cost-effective solution. The portfolio includes projects for Russian and foreign clients as well as some of patented developments.
Software Services, Security sensors for UAVs, motor vehicles, and robots; 3D reconstruction; Polarization; Neural networks; Stitching panoramas; Gesture recognition in stereo.
DeepGlint is an artificial intelligence company which specialize in both computer vision and deep learning technologies, and also develops the embedded hardware. The company provides big-data productions and solutions for customers. Its proprietary DeepGlint TechnologyTM is world-leading in detection, tracking and recognition of humans and vehicles. DeepGlint focuses on, but not limited to, public security, intelligent transportation and financial security. The company is also exploring on driverless vehicles, robotics and intelligent medical at the same time.
ENOT.ai specializes in neural network optimization, revolutionizing autonomous driving and Advanced Driver-Assistance Systems (ADAS). Their expertise in AI and LLM applications positions them at the forefront of automotive technology development. For more information.ENOT.ai was conceived by a seasoned team of computer vision solution developers. Collectively, we've spent several human lifetimes working with neural networks for a multitude of diverse companies. During this extensive period, we discerned computational inefficiencies in the existing neural network pipelines.
Our newfound understanding spurred the development of an innovative technology designed to substantially compress neural networks without impacting accuracy or performance. Initially employed internally, the potential to revolutionise AI developers' neural network pipelines soon became apparent. As a result, Enot.ai was formally established in 2021.
We enable intelligent vision for any product and application through the combination of patented panomorph optics and viewing.
By combining wide-angle panomorph optics and viewing functionalities, Immervision Enables is the true immersive experience. The logo is the mark of compatibility between any certified lens, product and software. Immervision Enables is the wide-angle standard for video and photography viewing.
IRIDA Labs is a platform-independent leading technology provider of software and silicon IPs for Embedded Video Processing.The company possesses significant knowledge in analysis, modeling, design and development of high-fidelity reference components and systems in Video Processing and Computer Vision, using state of the art CPU, GPU and DSP in the context of heterogeneous computing.Our product and technology portfolio includes embedded vision software and silicon IP for high throughput applications such as video stabilization, face detection and recognition, low-light video enhancement, HQV, pedestrian detection and traffic sign recognition addressing mobile, wearables, surveillance, automotive and consumer electronics.Founded in late 2007, IRIDA Labs is a privately-held company with headquarters in Patras, Greece and worldwide sales support, backed by VC and private investors.
IRIS-EnLight exploits sophisticated image and video processing technologies to enable high quality video under challenging lighting conditions in real-world applications like mobile phones, surveillance cameras and automotive. Images and videos captured in low-light conditions are facing two problems: Insufficient visual information and excessive noise. The IRIS-EnLight core simultaneously addresses these, in order to reach a clear and properly illuminant output.
IRIS-Enlight is not based in an HDR approach thus it does not suffer from the limitation of multi-frame HDR techniques (blurring, ghosting, etc). To this end, and due to the highly innovative techniques employed in this IP core, IRIS-EnLight is able to process video streams in real time and under any motion conditions, without limiting the freedom of the camera user. However, although it is not an HDR module, IRIS-EnLight has inherent HDR characteristics, being able to work evenly well in high dynamic range scenes.
Moreover, by using EnLight, integrators can significantly leverage the functionality and response of the device cameras, by allowing higher shutter speeds, which in other case would lead to darker results and inferior image quality.
IRIS-EnLight has been optimized for the challenging computational environment of mobile devices and can process video streams in real-time and with low-power. It incorporates a bundle of innovative color tone-mapping techniques as well as a proprietary video de-noising system providing high-quality results.
IRIS-ViSTA (video stabilization)
IRIS-VISTA is a unique video stabilization software module bringing advanced imaging capabilities to embedded systems. It is a flexible and scalable solution fully optimized to run in real-time using minimal processing workloads and very low memory bandwidth.
IRIS-VISTA has been optimized for the challenging computational environment of mobile devices and can process video in real-time. The combination of high-quality results and low computational requirements as well as low power consumption makes IRIS-VISTA an excellent solution for mobile appliances.
In addition to motion compensation, IRIS-VISTA allows for the correction of rolling shutter distortion which results in geometric image distortions and in the so called «jelly effect», often present in videos captured with CMOS camera sensors.
IRIS-VISTA – transforming your videos into memories you want to save and share.
MM Solutions AD is one of the largest mobile and industrial imaging companies. During the past 15 years, MMS established itself as well known and reliable partner for OEMs wanting to differentiate their imaging products by outstanding image quality, innovation, performance and robustness.
More than hundred mobile products are using MMS camera solutions and imaging algorithms, providing excellent imaging. Five of them were awarded by international photography association (TIPA) as best mobile imaging devices.
Partnering with the most popular SOC vendors and ramping up quickly on new platforms, MMS is targeting to become one-stop-shop for mobile, industrial and automotive imaging needs, providing algorithms and services needed to create best-in-class products.
Combined with the strong in-house expertize for Android/Linux/RTOS development, integration and testing, MMS brings significant value to customers products quality, usability, time to market, support and maintenance.
SW ISP, Bayer domain algos (temporal noise filters, aberrations corrections), YUV domain algos (edge enhancements, spatial and temporal filtering), Auto exposure, Auto white balance, Auto and continuous focus, Flash control, Computational camera (stereo, depth, object segmentations and tracking, fusion), CV algorithms porting and optimization.
MulticoreWare is multinational firm with offices in Silicon Valley, St. Louis & Champaign in USA, Changchun in China and Chennai in India. They have two business units, the Autonomous Vehicle and ADAS (AVA) Business Unit and the Media and Artificial Intelligence Analytics (MAIA) Business Unit. The AVA Business Unit focuses on Automobile-related Software Development and has a strong capability in image processing and sensor processing. The MAIA Business Unit focuses on Media-related Software Development including video encoders and decoders, machine learning and neural network related software development and compilers and tools focused on multicore platforms.
Machine Learning & Neural Networks: MulticoreWare has a team of researchers developing advanced CNN solutions and we are applying our expertise in heterogeneous computing to enable these applications on low-power embedded, FPGA, DSP, and GPU hardware.
Media Analytics & Data Extraction: MulticoreWare delivers AI-powered analytics solutions to extract and interpret actionable data from media streams. Our custom solutions can scale from the cloud down to smart cameras and embedded devices, and target use-cases in security, advertising, quality control, retail, broadcasting, and more.
Autonomous Vehicle Research: We combine our knowledge of machine learning, performance optimization, and safety-critical development to deliver solutions within the strict specifications of the industry.
H.265/HEVC Tools & Libraries: MulticoreWare founded and maintains the leading open-source H.265/HEVC encoder through the x265 project. HEVC is extremely compute-intensive and our expertise in performance optimization gave our x265 development team a critical advantage over traditional video codec vendors.
nViso is a leading provider of emotion recognition software that interprets human facial micro-expressions and eye movements captured through video. Its solutions use proprietary 3D facial imaging technology with artificial intelligence to track hundreds of different facial points to recognize human emotions. The company uniquely combines the latest advancements in computer science, engineering and behavioral sciences to make automatic emotion recognition a viable reality using any image based device. Its proprietary analytical techniques are based on theoretical work by Dr. Paul Ekman, which demonstrates that emotions can be precisely recognized by minor changes in micro-expressions in the face. nViso is based at the Swiss Federal Institute of Technology in Lausanne, Switzerland (EPFL)
3D facial imaging technology is a key component in a new
CEVA-XM4 and CEVA-XM6
wave of natural user interfaces (NUIs) that can analyze and understand facial movements. A primary use model of the nViso technology is to interpret people’s emotions by tracking hundreds of micro-expressions and movements to gain a more accurate and real-time understanding of the user’s emotional reactions to any media content, gaming or interactive experience. The nViso facial imaging engine is also able to recognize people’s age, gender, eye movements and other factors that can be used to deliver a more personalized experience to users.
PathPartner Technology is a leader in providing technology solutions and product engineering services for developing innovative intelligent devices. PathPartner offers a portfolio of enabling products and comprehensive services spanning embedded systems, hardware design, and system integration. We work with device manufacturers, system integrators and solution providers across diverse industry domains such as automotive, consumer electronics, audio systems, camera solutions, Internet of Things (IoT) etc. Our deep technology expertise in multimedia systems, deep learning solutions, vision-based systems, connectivity technologies, and imaging pipelines coupled with our experience in underlying hardware platforms, enables us to provide complete solutions to our customers while expediting their time to market, and future proofing investments.Headquartered in Bangalore, India, PathPartner has presence in USA, Europe and Japan.
Audio/Speech Processing: PathPartner develops, optimizes and integrates custom audio/speech processing pipelines for various smart and connected audio devices (Audio/speech codecs, Acoustic Echo Cancellation (AEC), Beamforming (BF), Noise Suppression (NS) and other pre/post-processing algorithms)
Video Processing: PathPartner develops, optimizes and integrates various video codecs and video pre/post processing algorithms for various consumer and automotive applications (H.264 codecs, HEVC codecs)
Machine Learning & Deep Learning: PathPartner develops and optimizes custom machine learning and deep learning algorithms for various use-cases spanning automotive, camera, consumer electronics, retail and other use-cases
Imaging solutions: PathPartner develops, optimizes and integrates single/multi-camera image processing pipeline algorithms on low-power embedded platforms
Pisoftware Technology Co., Ltd. (a.k.a. PiSofttech), headquartered in Shenzhen. China, is a tech-based startup focusing on intelligent vision methodologies and solutions. The company possesses state of the art technologies in computer vision and machine intelligence. Since its founding, PiSofttech with an outstanding reputation and performance has been providing quality and reliable solutions in panoramic VR, the 4D light field, industrial inspection, and biometrics. The panoramic VR system provides a complete solution including automatic calibration, multi-channel video/audio synchronization, color/vignetting correction, dynamic stitching, media encoding/decoding, live streaming, and real-time displaying. By utilizing the light field methodology, the panoramic acquisition device with multi-cameras can generate 6 DOF (Degree of Freedom) scenarios for VR and MR applications. Besides, the state of the art technologies based on pattern analysis and machine intelligence is introduced into the panoramic scenarios for further applications such as object detection, tracking, and personal authentication.
Pisofttech is a leading provider of panoramic solutions.
We provide binocular panoramic stitching SDK based on CEVA-XM4 platform to help panoramic product to achieve real-time high frame rate image stitching. Designed to be optimized for CEVA platform, our SDK can be integrated into the product system simply to ensure a fast and stable shipment.
We also provide SDK for panoramic APP on Android and IOS platform. Key features for this SDK: panoramic image preview, panoramic player, face beautification, social sharing (support Facebook, YouTube and other mainstream social platforms)
Visidon is a leading software vendor for mobile imaging. It specializes in innovative technology and solution development helping device manufacturers and service providers to create unique imaging experience. Visidon’s well known technologies for facial image analysis, object tracking and recognition are designed for embedded and mobile platforms being optimized for low computing and energy efficiency.Visidon is expert in developing image processing algorithms and computer vision technologies. Its software has been successfully deployed in handsets and tablet products worldwide helping device makers to differentiate with excellent imaging functionalities. New Visidon solutions for computational photography and image enhancement bring mobile image quality to totally new level and enable applications to entertain and make it easier for users to capture and enjoy great photos.
Visidon offers SDK products for various imaging applications, like face detection and tracking, smile and blink detection, age and gender recognition, face recognition, and face beautification that are technologies enabled by Visidon VDFaceSDK products. In addition to facial image processing software, Visidon offer SDKs for other camera and video solutions, such as object tracking, shake detection and low-light image capturing, for example. Visidon’s super fast and energy efficient software solutions are optimal for wide range of application with high requirements.
Listed by CB Insights as one of the 100 Most Promising AI Startups of 2023, Visionary.ai empowers cameras to capture video in extreme low-light and HDR. Their software-based image processing leverages edge AI to improve image quality in real-time to offer market-leading video quality.We are optic experts, computer vision engineers, and professional photographers, who have experienced the limitations of standard image signal processing. Our leadership team has pioneered computer vision algorithms over the past two decades, and worked on over 50 computer vision patents collectively.
Actt is a leading IP provider in China focusing on IP and SoC customization services. Actt has four product lines including high performance RF IP,low-power analog IP, high reliability eNVM IP, and high-speed interface IP.
These IP products are widely used in 5G, IoT, smart home, automotive, smart power, wearable, medical electronics, industrial and other fields.
Aricent is a global innovation technology and services firm focused exclusively on communications and a leading supplier of end-to-end LTE software frameworks as well as telecom design, R&D and integration services. The company’s library of over 125 licensable products, including communication modules and software stacks and pre-packaged frameworks jumpstart development cycles and help reduce design costs.
Aricent’s LTE UE Software Suite is a comprehensive software package which assists device manufacturers and chipset vendors in accelerating the development of LTE enabled devices. Aricent LTE UE software suite supports the CEVA-XC and CEVA-X DSP cores
ArrayComm is a provider of LTE and WiMAX physical layer solutions for wireless infrastructure and client device applications. ArrayComm is a world leader in Multi-Antenna Signal processing, delivering commercial A MAS™ software now that combines MIMO, beamforming, and interference cancellation to improve end user experiences and radio network economics through gains in coverage, client data rates, and system capacity. The company’s comprehensive and flexible PHY solutions include optimized DSP software and hardware accelerators that save development costs and time-to-market.
ArrayComm’s LTE eNodeB PHY is a fully scalable baseband physical layer solution incorporating industry-leading A-MAS™ multi-antenna signal processing software. ArrayComm have implemented their LTE eNodeB PHY on the CEVA-XC DSP core.
ASTRI’s core R&D competence in various areas is grouped under seven Technology Divisions, namely Communications Technologies, Electronics Components, Mixed Signal Systems IC, Advanced Digital Systems, Opto-electronics, Security and Data Sciences, and Intelligent Software and Systems. Five areas of applications including financial technologies, intelligent manufacturing, next generation network, health technologies, and smart city are identified for major pursuits.
Bluetooth Low Energy RF IPCSEM, founded in 1984, is a Swiss research and development center (public-private partnership) specializing in microtechnology, nanotechnology, microelectronics, system engineering, photovoltaics and communications technologies. Around 450 highly qualified specialists from various scientific and technical disciplines work for CSEM in Neuchâtel, Zurich, Muttenz, Alpnach, and Landquart.
Bluetooth Low Energy RF transceiver which provides the Physical Layer, Bit Stream Processing and Air interface Packet assembly and disassembly. It can support IEEE802.15.4 and proprietary standards from 62.5 kbps up to 4 Mbps.
Deutsche Telekom is one of the world's leading integrated telecommunications companies, with some 178 million mobile customers, 28 million fixed-network lines, and 20 million broadband lines. As mobile operator they provide fixed-network/broadband, mobile communications, Internet, and IPTV products and services for consumers, and information and communication technology (ICT) solutions for business and corporate customers.
IoT Solution Optimizer: Deutsche Telekom’s IoT Solution Optimizer is the first service which pairs technical IoT consultancy with a comprehensive solutions shelf. It is extremely easy to use, offering reliable guidance and exceptional choice throughout the process.
Founded in 2008, Galileo Satellite Navigation is a leading provider of software based GNSS receivers, GNSS simulators and GPS Indoor Navigation Infrastructure solutions.GSN’s GNSS portfolio allows mobile vendors, networking and digital home vendors to minimize costs and extend flexibility and robustness of their GNSS requirements.GSN’s software-based GNSS receiver not only reduces manufacturing costs – it provides superior flexibility, configurability, and upgradability.
Flexible software platform can be easily adapted to customer requirements.
Highly configurable to support a wide variety of applications.
Software platform offers simple upgradability and future-proof Enhance customer quality-of-experience, as the customer becomes part of the process
GPS receiver activity is optimized per-application, saving on battery resources.
Multi-system receiver – supporting GPS, GLONASS, Galileo, COMPASS, and SBAS
CEVA and GSN have partnered to offer a fully programmable GNSS Receiver IP core. The system fully supports GPS navigation and the solution scalability supports multiple GNSS constellations and A-GPS. Minimal hardware accelerators can reduce power consumption by as much as half. The receiver supports snapshot operation mode for ultra-low-power mobile scenarios. The GNSS IP Core architecture supports CEVA-XC Core as well as CEVA-TeakLite-III and delivers outstanding performance while maintaining minimal consumption of its processing power and without compromising on power consumption.
As an experienced CEVAnet partner, GSN provides highly-optimized GNSS IP integration, assuring highly reliable performance and quick time-to-market. CEVA’s DSP cores provide industry-leading processing power, ensuring future-proof performance as requirements evolve. Existing CEVA customers may be able to utilize their CEVA DSP for existing and future solutions to added embedded GPS capabilities.
GPS block diagram implementation using CEVA-TeakLite-III
GSN’s soft GNSS receiver running on CEVA-XC is a powerful IP core which is designed to interface with host processors in navigation and mobile platforms. This powerful GNSS soft receiver integrates with any RF frontend without any hardware add-ons, significantly minimizing the silicon footprint of the solution. The receiver includes a powerful baseband software signal processing engine to achieve the highest positioning performance even at low signal level conditions.
GMV is a privately owned technological business group with an international presence. Founded in 1984, GMV offers its solutions, services and products in very diverse sectors: Aeronautics, Banking and Finances, Space, Defense, Health, Security, Transportation, Telecommunications, and Information Technology for Public Administration and large corporations.
Since early 2000, Global Wireless Technologies (“GWT”) has been a design and developer of wireless solutions for the cellular communications markets.Drawing on its software library and technical expertise, GWT has developed multi-standard solutions. These solutions are aimed at resolving challenges and fulfilling requirements in the commercial cellular, government, and test & measurement markets.GWT’s focus on flexibility, price, efficiencies (size, scalability, power, output, ease of integration), quality, coupled with our technical expertise and emphasis on customer satisfaction enable us to provide superior solutions for customers in well-defined and niche markets.
Idea! Electronic Systems is a leading engineering design-house and IP provider for the Digital TV industry. The company’s best-in-class technology and IP portfolio includes complex DTV modulators and demodulators for a variety of standards including DVB-S, DVB-S2, DVB-C and ISDB-T, as well as other components of the Digital TV system such as Digital Frontend and FEC IPs. The company’s DSP based demodulation solutions significantly save development costs and time-to-market of multimode DTV demodulators.
Idea! Electronic Systems offers a complete software based ISDB-T solution implemented on the CEVA-XC DSP core. The ISDB-T solution is based on CEVA’s Multimode DTV reference Architecture enabling running multiple DTV standards on the same programmable platform.
PA is a global technical consultancy firm, with a strong team focused on communication and wireless technologies. PA offers wide range of software radio solutions and services for 3G Layer-1 Signal Processing and has a strong experience with DSP processors. PA also provides independent technical support and advisory for vendors, regulators, operators and users of mobile systems.
PA Consulting offers integrated 3G (HSPA) PHY software optimized for the CEVA-XC323 targeting all different wireless infrastructure applications from Femto up to Macro.
Established in 2018 in Taipei, Taiwan, by a group of seasoned experts, Sirius Wireless provides RF silicon intellectual property, with a focus on consumer IoT wireless standards, including Bluetooth and Wi-Fi.
TurboConcept is an industry-reference provider of Intellectual Property Cores (IP Cores) for turbo and LDPC codes. Since the company was created in 1999 we have been at the forefront of innovation in Forward Error Correction (FEC). TurboConcept has been contributing actively in open standardization bodies like DVB and has developed a large product portfolio of standard and proprietary customized solutions. More than 50 License Agreements have been registered with customers convinced with the high quality and reliability of our products.
TurboConcept provides silicon-proven wireless PHY Cores offering the best level of performance in terms of silicon cost and power consumption and support three PHY layer specifications: HSPA, LTE and WiMAX.
Alango is a leading provider of voice processing technologies for mobile and other types of voice communications. Alango technologies are distinguished by high voice quality as well as their robustness to different types of noises and possible non-linear distortions in a voice communication system. Alango technologies are designed to provide maximum ease of integration into baseband software as well as other applications and computational environments. They require little fine-tuning for a specific acoustic environment or product. Besides, developed auxiliary procedures allow automatic estimation of acoustic parameters of a product and technology fine-tuning providing the best possible performance.Significant Alango advantages are its flexibility in its business model and excellent support provided to technology licensees and equipment manufacturers.
Acoustic Echo Cancellation with residual echo suppressor and comfort noise generator;
Automatic Gain Control with fast release time and high robustness to noise;
Noise Suppression; – Multipband Dynamic Range Compression for speech ineligibility enhancement;
There are Full, Lite and Compact versions of the package implementing different tradeoffs between MIPS, Memory and processing delay parameters. These versions cover all possible types of applications providing the best possible performance for available resources.
Technologies from the Voice Communication Package are very well integrated with each other sharing the same subband decomposition schemes and some computational blocks. However, if necessary, each of them can be used as a standalone technology.
These microphone array technologies allow building adaptive directional microphones of different directivity order utilizing 2 or more omnidirectional microphones. Applications include advanced mobile phones as well as more traditional applications for directional microphones., ADM provides the following advantages over conventional, acoustic directional microphones:
Better SNR improvements;
Much easier to build into a mobile device;
Very low sensitivity to wind;
No proximity effect;
There are two version of ADM technology:
Low delay version for real life sound reinforcement systems with overall delay less than 4ms;
Low MIPS version for mobile communications sharing the subband decomposition scheme with Voice Communication Package;
Noise Dependent Equalization (NDE)
Noise Dependent Equalization dynamically changes/equalizes the sound produced by a mobile communication device speaker according to user’s environment. The objective of the technology is to modify the reproduced sound in way so that it is always intelligible but not annoyingly loud in changing noisy conditions. This is achieved by monitoring the intensity and spectral properties of the environmental noise and modifying the reproduced sound accordingly. This technology virtually eliminates the need for volume control on mobile communication devices such as mobile phones and hands-free car kit.
OptimSpeaker 2 Lite, Classic and Premium.
All of the ARKAMYS OptimSpeaker 2 solutions offer a powerful combination of embedded software, tools, and processes to compensate for the audio limitations typical of smartphones, tablets, and wearables. By combining ARKAMYS newest software with top-notch SAT (Sound Adjustment Toolset) cutting edge algorithms and audio expertise, this sound optimization technology improves audio spaciousness and clarity while respecting the original timbre of every sound.
Bongiovi Acoustics is the developer and patent holder of the award-winning Digital Power Station ™ technology, the Ultimate Audio Solution for any product or service with sound.
Bongiovi DPS is a patented algorithm that optimizes audio in real time.
DPS Profiles are created and implemented for ultimate audio flexibility in any sound scenario.
At the heart of DPS is our profile system. A DPS profile contains over 120 calibration points that configures the patented DPS algorithm. Each profile is carefully crafted by Bongiovi acoustic engineers. These profiles are used to optimize the audio signal in real-time; for the output device (speakers), environment (high noise), and to emphasize a “sound” or other desired effects.
Cyberon Corporation, with its headquarter in Taipei, Taiwan, is a leading embedded speech solution provider and supported by experts experienced in Speech Recognition and Text-to-Speech technologies for tens of years. Cyberon's speech solution is developed specifically for mobile & portable devices to provide users a convenient, natural and reliable user experience.
Low bit rates speech compression solutions including AMBE® vocoders
Founded in 1988, Digital Voice Systems, Inc. (DVSI) of Westford, Massachusetts, is a world leader in the development of low data rate, high-quality speech compression products used in digital communications and storage applications.
Digital Wave reference source code is strictly in accordance with DRA technical specification and optimized to various platforms. Coding Algorithm optimization mainly aims to adjust the algorithm parameters in different transmission rate, in order to obtain a better coding effect.
Founded in 2001, Dirac Research is a premier R&D company specializing in high-performance digital sound optimization, room correction and sound field synthesis. The company was founded by researchers from the Signals & Systems Group of Uppsala University, Sweden, which has fostered 8 Nobel Prize laureates. With Dirac’s patented toolbox for efficient and accurate audio system optimization, customers such as BMW, Bentley, Rolls Royce and Datasat Digital Entertainment have achieved dramatically improved sound quality and a shortened time-to-market.
The Dirac HD Sound solution is a mixed-phase loudspeaker correction technology that optimizes a sound system’s transient reproduction and frequency response for optimal performance and clarity. This software offering has now been fully optimized for the native 32-bit processing capabilities of the CEVA-TeakLite-III architecture, ensuring a cost-efficient low power and low system overhead solution, even within constrained systems. The Dirac HD Sound technology has been proven across a range of high-end audio applications in the consumer, cinema, professional and automotive markets. The technology is customized to a specific sound device and enhances many audio and voice aspects, including voice correction, stereo image correction, bass correction, listening fatigue minimization, and tonal and transient correction. Resonances, diffraction, group delay errors, etc., are all minimized.
Further advantages include the following:
Sound system design flexibility is greatly enhanced by the ability to tailor the loudspeaker/earphone response digitally without hardware changes.
Similar sound characteristics can be achieved across multi-sourced speaker/earphone solutions by applying customized filters with the same target response.
Better and less expensive loudspeakers/earphones (“smart speakers”) can be obtained by designing them grounds up with Dirac HD Sound, for example extending the bass response of a small enclosure such as in flat-screen TV
Brings out the full potential of any playback system, regardless of acoustic design limitations such as encountered in the mobile and TV industries
Dolby Laboratories is a recognized innovator in audio entertainment. Established by Ray Dolby, the company first developed noise reduction systems to improve recorded sound quality. Now, the name Dolby is synonymous with quality audio throughout the world.
DSP Concepts accelerates the development of embedded audio products the agile way with its advanced Audio Weaver® technology.At DSP Concepts, we believe that development of products is optimized through global collaboration and integration of tools, technologies and people. As product cycles shorten and technologies get more complex, efficient collaboration and technology integration becomes essential to the success of a company.
Audio Weaver® lets product-makers add digital audio features with extreme efficiency. Audio Weaver is built around the Awe Core™ Soft-DSP™, software-based audio processor, and Audio Weaver Designer™, an intuitive configuration-tool for Awe Core.
Audio Weaver® Advantages:
Rapid Product Development – Audio Weaver® allows product designers and engineers to integrate, invent, and fine-tune audio-features at unprecedented speeds. The ability to change signal-processing layouts in real-time yields incredibly fast iteration times.
Processor Agnostic – Audio Weaver® designs (“Layouts”) are fully portable across all processors supported by the Awe Core™, including CEVA’s audio DSPs CEVA-X2 and CEVA-BX family. Audio Weaver’s real-time MIPs and Memory profiling empowers system architects make fast, reliable decisions about processor selection.
Powerful – with more than 400 processing modules now available, Audio Weaver® easily meet the needs of any application that requires audio processing. Its modules can be combined and adjusted to suit the needs of many markets, including automotive, IoT, consumer and pro audio, security, and more.
Cost-effective – Audio Weaver® reduces development costs in numerous ways. Its modular, real-time programming environment allows product development teams to quickly create new audio processing chains, with no coding skills required.
DTS, Inc. (NASDAQ:DTSI) is dedicated to making digital entertainment exciting, engaging and effortless by providing state-of-the-art audio technology to hundreds of millions of DTS-licensed consumer electronics products worldwide. From a renowned legacy as a pioneer in multi-channel audio, DTS became a mandatory audio format in the Blu-ray Disc™ standard and is now increasingly deployed in enabling digital delivery of movies and other forms of digital entertainment on a growing array of network-connected consumer devices. DTS technology is in home theaters, car audio systems, PCs, game consoles, DVD players, televisions, digital media players, set-top boxes, smart phones, surround music software and every device capable of playing Blu-ray discs. Founded in 1993, DTS’ corporate headquarters are located in Calabasas, California with its licensing operations headquartered in Limerick, Ireland.
INNER BEAUTY engine replaces the traditional hardware infrared sensor currently used in most phones and allows for a beautifully designed full-screen device. It uses the Ultrasound Virtual Proximity sensor.
Hardware-based optical sensors have been an indispensable part of every smartphone to turn off the screen and to disable touch functionality when a user holds a device to their ear. By replacing these hardware components with Elliptic Labs’ INNER BEAUTY—the first software-based solution to replace the optical proximity sensor—the unsightly black holes on the front of the smartphone will be removed. The result is a more aesthetically pleasing design.
Fluent.ai develops highly accurate and intuitive speech understanding solutions in a small footprint and low latency package capable of running fully offline on small devices. Our solutions enable consumer electronic device manufacturers and OEMs to develop unique and secure voice user interface solutions for their devices. Our patented speech-to-intent approach allows the development of speech recognition models in any existing language and offers unmatched multilingual capabilities.
IFLYTEK CO., LTD. (iFLYTEK) is a national key software enterprise dedicated to the research of intelligent speech and language technologies, development of software and chip products, provision of speech information services, and integration of E-government systems. The intelligent speech technology of iFLYTEK, the core technology of the company, represents the top level in the world.
The Windows Media Audio decoder decodes audio streams that were encoded by the Windows Media Audio Encoder. The encoder and decoder support three categories of encoded audio: Windows Media Audio Standard, Windows Media Audio Professional, and Windows Media Audio Lossless.
Founded in 2014 in Berlin, Mimi Hearing Technologies is a world-leading provider of digital healthcare hearing tests and hearing-ability-based sound personalization. Born out of years of scientific research, Mimi aims to give listeners the best possible audio experience driven by a commitment to hearing health across any device tailored to the individual listener. Mimi wants to create a world where hearing is no longer a barrier to interaction and enjoyment. The company’s website can be found at https://mimi.io.Mimi products and integrations have won numerous international awards, including the EISA Best Buy OLED TV (2021-2022) for sound personalization in TP Vision Philips TV, the CES Innovation Award (2019 & 2018) for sound personalization in Beyerdynamic headphones, the SATVISION Innovation Prize (2018) for sound optimization in Loewe TVs, the Sonar+D Award for Innovation (2017), StartUps & Developer Award at the San Francisco Music Tech Summit (2017) and the IFA Berlin Prize for Audio Innovation (2017).
Rubidium Ltd. is a leading developer of Speech Processing solutions that cover the entire spectrum of voice dialog systems: input, output and interaction. Rubidium’s development team is made up of expert DSP engineers and sound professionals. With over seventeen years experience in the market, we are constantly innovating and raising the bar in areas such as speech recognition (ASR), text-to-speech (TTS), speech compression and storage, biometric speaker identification/verification, beamforming and handsfree voice-trigger features. We take great pride in helping OEMs and product designers provide their customers with a reliable, accurate, hands-free and productive user experience. Our low cost, small footprint, multi-lingual Voice User Interface (VUI) solutions enable consumer and mobile product developers to introduce the sleekest user-friendly products to market, while ensuring a quick development cycle and keeping their BOM as low as possible.
Rubidium’s software has been optimized to leverage the power and flexibility of the TeakLite DSP family, delivering outstanding performance for any advanced, voice-enabled application
Rubidium’s speech processing technologies, developed in-house by a team of experts with years of hands-on scientific and industry experience, are available as optimized software libraries. The following are some of Rubidium’s core technology offerings:
Automatic Speech Recognition – Small vocabulary, multi-lingual, command-and-control technology to easily and safely control any set of functions through voice commands. For example: call acceptance/rejection, device setup and installation procedure (pairing/calibration/interconnection, etc.), music streaming control, machine operation, handsfree lever/switch/keypad replacement, etc.
Text to Speech – Announces textual content such as names, numbers and phrases in a range of languages with a natural, warm, human-sounding voice.
Biometric Speaker Verification – Offers a small footprint and a low-cost design for effective biometric identification and authentication on any consumer product or mass market device.
Compressed Speech Coding/Playback/Storage – Speech compression algorithms offer storage and playback, or transmission of recorded speech that can be used to play user instruction prompts, device status indications, alert messages, entertaining content, memo recordings or even real-time speech channels. Rubidium also provides support for development of new interaction languages, software code porting, optimization, integration, customization and engineering requirements specific to our customers’ software or hardware platforms.
Sensory, Inc. is the leader in speech technologies for consumer products, offering a complete line of IC and software-only solutions for speech recognition, speech synthesis, speaker verification, music synthesis and more. Sensory’s products are widely deployed in consumer electronic applications including Smart Phones, Automotive, Bluetooth™ products, toys, and various home electronics. Sensory’s customers represent the leaders in consumer electronics, including such companies as AT&T, BlueAnt Wireless, Hasbro, JVC, Kenwood, Mattel, Mitsubishi, Toshiba, Uniden, VTech, Samsung and Sony.
Sensory’s TrulyHandsfree™ Voice Control technology builds upon the initial success of TrulyHandsfree™ Trigger, and now offers multiple phrase technology that recognizes, analyzes and responds to dozens of keywords. It consistently recognizes phrases even when embedded in sentences and surrounded by noise. Traditional approaches to keyword spotting have failed in high noise and frequently false fire, but TrulyHandsfree™ has excellent accuracy without false fires even in high noise and speech. Smartphones, Bluetooth devices and consumer electronics for the home and the car can now offer a TrulyHandsfree experience from beginning to end. The fully programmable CEVA-TeakLite-4 DSP enables the lowest power TrulyHandsfree implementation in the market, while leaving plenty of headroom to support other audio/voice related functions in software.
VOCAL Technologies, Ltd. (VOCAL.com), founded in 1986, is a leading designer of software and hardware solutions under license for voice, video, and facsimile and data communications. The company develops and applies advanced technologies for superior voice, video, fax and data communications. VOCAL is dedicated to providing our clients innovative design solutions for the highest quality communications at the lowest cost.
VOCAL provides a broad range of Voice design solutions to support a variety of voice applications as well as voice communications over radio, mobile, PSTN and IP networks. Our voice designs may be configured from a suite of speech compression, echo cancellation, noise reduction and beamforming solutions to support your specific development effort.
Voice Compression– ITU, GSM, wideband and industry standard voice codecs
Echo Cancellation– ITU compliant line/network and acoustic echo cancellers
Noise Reduction– reduce background noise in challenging environments
Adaptive Beamforming– acoustic beamformers for hands-free, mobile and voice conferencing applications
Voice Quality Enhancement– a comprehensive, easily configurable voice solution
Waves is the world’s leading developer of audio plugins and signal processors for the professional and consumer electronics audio markets. Waves’ Maxx® technologies leverage its expertise in psycho-acoustics to provide custom semiconductor and DSP licensing solutions to consumer audio manufacturers worldwide. These solutions compensate for the acoustic quality limitations from small, power efficient speakers systems found in today’s most popular CE products such as LCD TVs, notebook PCs, portable speaker systems, and mobile phones. Maxx® is already being used by some of the most important audio and consumer electronic firms in the world including Dell, Asus, Altec Lansing, Audio Products International, Clarion, JVC, Microsoft, Samsung, Sanyo and Sony.
Maxx by Waves currently offers three customizable suites of audio enhancement technologies, for both input and output processing: MaxxAudio for studio-quality music, movies and games; MaxxVoice for voice communications; and MaxxSpeech for improved Automatic Speech Recognition performance.
"Ceva is an ideal company to work with THX to take spatial audio solutions to the next level given its synergistic voice, audio and sensor fusion solutions and embedded systems expertise. I look forward to working with CEVA to create further enhanced entertainment experiences for our customers."
Bosch Sensortec GmbH is a fully owned subsidiary of Robert Bosch GmbH dedicated to the world of consumer electronics; offering a complete portfolio of micro-electro-mechanical systems (MEMS) based sensors and solutions that enable mobile devices to feel and sense the world around them. Bosch Sensortec develops and markets a broad portfolio of MEMS sensors, solutions and systems for applications in smartphones, tablets, wearable devices, and various products within the IoT (Internet of Things).
The Bosch Sensortec portfolio of motion sensors includes gesture- and motion-based products: Accelerometers, Gyroscopes, Geomagnetic sensors, eCompass, Inertial Measurement Units, Absolute Orientation sensors, Smart Hubs & Nodes as well as the Sensor Fusion software. Motion sensors are designed for various applications in the field of Mobile devices, Wearables, IoT and Smart Home, Gaming and Imaging devices as well as Industrial applications.
InvenSense, Inc., a TDK Group company, is a world leading provider of MEMS sensor platforms. InvenSense’s vision of Sensing Everything® targets the consumer electronics and industrial areas with integrated Motion and Sound solutions. InvenSense’s solutions combine MEMS (micro electrical mechanical systems) sensors, such as accelerometers, gyroscopes, compasses, and microphones with proprietary algorithms and firmware that intelligently process, synthesize, and calibrate the output of sensors, maximizing performance and accuracy. InvenSense’s motion tracking, audio and location platforms, and services can be found in Mobile, Wearables, Smart Home, Industrial, Automotive, and IoT products. In May of 2017, InvenSense became part of the MEMS Sensors Business Group within the newly formed Sensor Systems Business Company of TDK Corporation. InvenSense is headquartered in San Jose, California and has offices worldwide.
TDK offers MEMS products, such as accelerometers and gyroscopes used in navigation, motion tracking and motion control, as well as optical stabilization.
Renesas Electronics Corporation delivers trusted embedded design innovation with complete semiconductor solutions that enable billions of connected, intelligent devices to enhance the way people work and live. A global leader in microcontrollers, analog, power, and SoC products, Renesas provides comprehensive solutions for a broad range of automotive, industrial, home electronics, office automation, and information communication technology applications that help shape a limitless future.Renesas' mission is to develop a safer, healthier, greener, and smarter world by providing intelligence to its four focus growth segments: Automotive, Industrial, Infrastructure, and IoT that are all vital to our daily lives, meaning its products and solutions are embedded everywhere.
Renesas delivers products and solutions that bring intelligence to four focus growth segments: Automotive, Industrial, Infrastructure, and IoT
Renesas provides a vast array of semiconductor products, from sensors to actuators, across the whole signal chain to help its customers realize complete embedded systems
Renesas offers a wide variety of software, boards, simulation & design tools, etc, to make its customers’ lives easier
Renesas also has a robust ecosystem where Renesas certified partners with expertise in Renesas products support Renesas’ customers at every stage of their design so that they achieve their goals
ST is a global semiconductor company with net revenues of US$ 9.66 billion in 2018.Offering one of the industry’s broadest product portfolios, STMicroelectronics is a world leader in providing the semiconductor solutions that make a positive contribution to people’s lives, today and into the future. By getting more from technology to get more from life, ST stands for life.augmented.
Arteris, provides Network-on-Chip interconnect IP and tools to accelerate System-on-Chip semiconductor (SoC) assembly for a wide range of applications. Results obtained by using the Arteris product line include lower power, higher performance, more efficient design reuse and faster development of ICs, SoCs and FPGAs.
Partner Type
Complementary IP
CEVA IP supported
CEVA DSP Cores
Product Offering
CEVA and Arteris have collaborated to bring Arteris’ advanced FlexNoC interconnect IP together with CEVA’s industry-leading DSP cores in a highly-optimized, high performance multi-core solution.
ProteanTecs is the leading provider of deep data analytics for advanced electronics monitoring. Trusted by global leaders in the datacenter, automotive, communications and mobile markets, the company provides system health and performance monitoring, from production to the field. By applying machine learning to novel data created by on-chip monitors, the company's deep data analytics solutions deliver unparalleled visibility and actionable insights—leading to new levels of quality and reliability.
RISC-V (pronounced “risk-five”) is an open, free ISA enabling a new era of processor innovation through open standard collaboration. Founded in 2015, the RISC-V Foundation comprises more than 100 members building the first open, collaborative community of software and hardware innovators powering innovation at the edge forward. Born in academia and research, RISC-V ISA delivers a new level of free, extensible software and hardware freedom on architecture, paving the way for the next 50 years of computing design and innovation.The RISC-V Foundation, a non-profit corporation controlled by its members, directs the future development and drives the adoption of the RISC-V ISA. Members of the RISC-V Foundation have access to and participate in the development of the RISC-V ISA specifications and related HW / SW ecosystem. The Foundation has a Board of Directors comprising seven representatives from Bluespec, Inc.; Google; Microsemi; NVIDIA; NXP; University of California, Berkeley; and Western Digital.
Founded in 2003, Alchip Technologies is a global leading provider of ASIC design and production services for system companies developing complex and high-volume ASIC/SoC. Alchip provides the fastest time-to-market and cost effective solutions for SoC design with 28/20/16nm and 7nm advanced processes. Our customers include the global leaders in AI, HPC/Supercomputing, consumer electronics devices like cameras, mobile phones, entertainment devices, networking, and other electronic products. Alchip is a public traded company listed on the Taiwan Stock Exchange with the stock ticker number 3661.
Alchip’s major products can be divided into four categories. First, in HDTV market, Alchip has designed over 40 SoC for HDTV including 4K/UHD TV. In the future, high performance TV will not only be an entertainment system as before, but also an information and multimedia center through the Internet. Furthermore, the market in Networking is surging. Alchip leads the trends of 4G Low Power Design and cooperates with clients to offer 3G and 4G TD-LTE Baseband solutions. Moreover, to dominate the competitive consumer-electronics market, Alchip provides customers with the fastest time-to-market and the lowest cost of solutions. Last, in niche market, Alchip offers remarkable ASIC design and production solutions in supercomputers, Bitcoin mining machine, surveillance, entertaining system and medical imaging systems.
ARM is the industry’s leading provider of 16/32-bit embedded RISC microprocessor solutions. The company licenses its high-performance, low-cost, power-efficient RISC processors, peripherals, and system-on-chip designs to leading international electronics companies. ARM provides its Partners with a total technology solution comprising cores, tools, platforms, and other Intellectual Property (IP) components required in developing a complete system.
The ARM RealView Developer Suite multi-core debug solution provides the facility to debug multiple ARM plus DSP cores using a single debug environment. The RealView multi-core debug tools consist of:
RealView Developer Suite RVD Debugger
RealView RVI run control unit for hardware debug
RealView Developer Suite add-on options for DSP debug
Brite Semiconductor is a world-leading ASIC design solution provider, targeting at ULSI ASIC/SoC chip design on SMIC advanced 55nm/40nm/28nm process technology and turn-Key solutions. Brite Semiconductor provides flexible one-stop services from RTL/netlist to chip delivery, and seamless, low-cost, and low-risk solutions to customers.Brite Semiconductor also provides comprehensive silicon proven “YOUTM” IP portfolio and silicon platform solution, which can be widely adopted in consumer electronics, IoT, wearable devices, communications and computers, as well as industrial and municipal areas. As part of YouIP portfolio, YouSiP (Silicon-Platform) solution provides a prototype design reference for system house and fabless to differentiate their products and win the market rapidly.Brite Semiconductor was founded in 2008 by venture capital firms from China and abroad, and collaborated with Semiconductor Manufacturing International Corporation (SMIC) as strategic partners in 2010. Headquarter in Shanghai, Brite has two subsidiaries of Beijing Brite IP and Hefei Brite Technology and has set up offices in US, Europe, Japan and Taiwan providing services to customers.
Ellisys is a leading worldwide supplier of advanced protocol test solutions for Bluetooth®, Wi-Fi®, WPAN, USB 2.0, SuperSpeed USB 3.1, USB Power Delivery, USB Type-C™, DisplayPort™, and Thunderbolt™ technologies.
The greatly increased functionality incorporated in today’s IC designs must use existing proven IP components to meet market windows. However, there are too many different kinds of IP due to function requirements and technology node differences for any one company to provide. As part of GUC’s total solution for customers, GUC’s IP Eco-System allows you to work with products from GUC, TSMC and other IP vendors to provide the widest range of design options for designers to complete their projects in a timely and cost-efficient way.
Lauterbach is the leading manufacturer of JTAG debuggers and real-time trace tools. Highest quality, innovation and expert support have lead to Lauterbach’s worldwide leadership in the JTAG and in-circuit-emulator market. It is an international, well-established company with branch offices in the US, Europe, Japan and China.
Lauterbach’s Trace32-PowerDebug enables CEVA customers to conduct real-time debugging of multi-core environments that incorporate CEVA DSPs.
The TRACE32-Powerdebug supports Multi-Core debugging together with other cores (e.g. ARM, MIPS or C166). All trigger and trace features of the chip are supported. Graphical variable displays and dedicated commands to handle large arrays support the development of DSP specific code.
Working together, Lauterbach and CEVA significantly accelerate application and chip development for complex, multi-core System-on-Chip (SoC) thanks to concurrent multi-core debugging of CEVA DSP Cores. This is a key element in the development and testing of SoC design where successfully debugging an application running simultaneously on two or more processors is vital to meeting a project’s timeline and its time-to-market. Lauterbach’s TRACE32 Debugger works with either multiple CEVA DSP cores or a combined CEVA DSP and other microprocessors.
MooreElite is a world-leading IC design accelerator, providing ASIC design and turn-key solutions across multiple market sectors. MooreElite strives to provide one-stop services from RTL/SPEC/FPGA to chip delivery. Our services include but are not limited to: Chip Architecture Planning, IP Selection, Digital Frontend Design, DFT, Digital Verification, Physical Design, Layout, Tape-Out, Assembly and Testing services. Our team has been serving customers with knowledge of how to get the most out of silicon since 2012, offering maximum flexibility with turn-key, NRE, consulting and on-site support services. Headquartered in Shanghai, MooreElite has offices in Beijing, Shenzhen, Hefei, Chongqing, Suzhou, Guangzhou, Chengdu, Xi'an, Nanjing, Xiamen, Hsinchu and San Jose.
Partner Type
Design Services and Development Tools
Product Offering
MooreElite has launched the IP Cloud service in July 2018 with the most comprehensive IP platform in Chinese Semiconductor industry. The platform strives to be the “Google” of Silicon IP; it is already the one stop station that represents more than 100 leading IP suppliers for IC designers seeking IP solutions. Responding to the high demand from the Chinese market, CEVA has offered the IP solutions in the portal, http://cloud.mooreelite.com/ip. MooreElite IP Cloud platform will also be providing valuable functional assistance for global IP providers and designers with constantly updated News Center and Knowledge Center databases in future updates.
MosChip is an end-to-end product development companyEstablished in 2000, MosChip is the First Fabless Semiconductor Public Company traded in India with 18+ years of experience. MosChip is an end-to-end product development company with focus on Product Engineering in Mixed signal IP, Turnkey ASICs, Semiconductor and IOT solutions catering to the Aerospace and Defence, Consumer Electronics, Automotive, Medical, Networking & Telecommunications, and Mobile industries.Our unique processes are specifically designed to comply with the high performance and long-term reliability needs of our customers.Over the past decade, MosChip has gained products and technology diversity, complexities, time-to-market expectations and a balance between global market needs.
TandemG is a software and hardware R&D service provider that specializes in providing solutions to companies around the world. Its client base spans around a range of companies, from startups and up to market leaders. The company’s areas of expertise include RT & Embedded systems, Windows Kernel & Internals, Mobile & Desktop applications and Electronic design.
TandemG specializes in complete solutions, design and implementation involving a wide range of CEVA’s DSPs. TandemG has vast proven experience in definition, architecture, design, implementation and integration. TandemG is all about tailoring suited solutions for embedded and mobile applications according to customer needs.
P-Product is a CEVA certified software design center. It specializes in developing, optimizing and porting communications, audio and video algorithms and applications for embedded CEVA DSP platforms. P-Product has extensive expertise in LTE and WiMAX technologies.
P-Product develops efficient implementations of digital signal processing software based on standard or custom specifications using algorithm optimizations and deep implementation optimization. The company has extensive experience in audio and video codec porting.
UltraSoC’s technology helps SoC developers design & debug complicated chips, particularly multi-core The company’s semiconductor IP and software products gives engineers and architects full visibility: making it easy to understand everything in a chip, identify problems, tune performance, reduce power consumption and reduce cost.
By hard-wiring non-intrusive vendor-neutral analytics circuitry into the chip, UltraSoC accelerates time-to-market, reduces bugs and increases quality, de-risking the SoC development process.
UltraSoC provides a library of IP components designed to instrument SoC or FPGA designs. Its modular, message-based architecture gathers information about the behavior of the system, non-intrusively and at wire speed to help debugging, development and optimization. UltraSoC blocks are delivered as parameterized soft cores, allowing capabilities to be balanced against gate count according to the needs of the application on a per-instance basis.
This can help identify problems, measure performance, improve operations, reduce power consumption or identify inefficiencies to enable cost reduction.
Veriest is headquartered in Israel with a R&D site in Belgrade, Serbia. Our team has accumulated a wealth of experience through our involvement in projects in the forefront of semiconductor technology. Veriest maintains unrivaled quality standards in terms of both service and knowledge.
Partner Type
Design Services and Development Tools
Product Offering
With the ability to take on all significant parts of the design process ourselves, we offer detailed expertise coupled with a big-picture view that enables us to successfully address any issue that arises during the verification process. By demanding complete accuracy and taking into account all the intricacies of each specific case, including schedules, resource limitations and technical specifications, Veriest is able to achieve the very best levels of efficiency.
VWorks is an industry leader in the development of new technology and business solutions for electronic system level development. VWorks seeks to advance and proliferate the use of modeling, simulation, virtual prototyping and other computer software based means for enhancing the capabilities of electronic system level design technology and reducing or eliminating the need for physical lab set ups, hardware prototypes, multiple hardware revisions, and throw away hardware.
Since 1990, CMX Systems has offered very small and blazingly fast Real Time Operating Systems (RTOS), TCP/IP stacks, CANopen protocols, and Flash File Systems for virtually any embedded application. CMX also distributes a significant number of compiler tools from a variety of popular manufacturers to provide a single purchasing source for embedded designers. All CMX software is economically priced, requires no royalties, and features free source code and fast, expert technical support.
CMX-RTX is a truly preemptive, multi-tasking RTOS supporting the Palm and Teaklite series of processors. This “lean and mean” RTOS offers the smallest footprint, the fastest context switching times, and the lowest interrupt latency times available on the market today. CMX-RTX is licensed with a low, one-time fee and features full source code, no royalties on shipped products and free technical support and software updates.
Enea’s flagship product family, OSE™, was introduced in 1984, and has become the world’s most tested and trusted real-time operating system. OSEck (OSE Compact Kernel) is a DSP-optimized version of Enea’s full-featured OSE RTOS. Occupying as little as 8 kbytes of memory, OSEck delivers fully-preemptive, event-driven real-time response and features built-in error detection and handling. This combination makes OSEck ideal for telecom, datacom, automotive, industrial control, medical and mil/aero applications with tight memory constraints that require reliable real-time control and signal processing.
FreeRTOS is the market leading real time operating system (or RTOS), and the de-facto standard solution for microcontrollers and small microprocessors.
Count on Quadros Systems to provide you with the right technology for your embedded project. From real-time operating systems to file systems; from embedded USB solutions to high performance TCP/IP stacks, we have what you need to complete a successful development project.
Partner Type
RTOS
CEVA IP supported
CEVA-X1622
CEVA-X1641
CEVA-X1643
Product Offering
The RTXC RTOS has been leading the way in innovation. The breakthrough RTXC Quadros RTOS is a fundamentally different approach to real-time operating systems.
We have designed our RTOS to address the changing requirements of embedded systems:
Small footprint
Powerful performance
Reliable operation
Highly efficient processing
We are not content to continue to sell technology that is just “good enough.” Our multi-kernel approach is based on the fact that no single processing model can hope to address the needs of all embedded applications. We used our years of RTOS experience as a launching pad for this new design that provides the flexibility to efficiently support the divergent needs of embedded platforms: DSP, MCU, MPU, convergent (DSP+MPU) and multicore.
RT-Thread it's an open-source, neutral, and community-based real-time operating system (RTOS). The software has the characteristics of very low resource occupancy, high reliability, high scalability, can be greatly used in sensing nodes, wireless connection chips and many resource-constrained scenes, also widely applied in gateway, IPC, smart speakers, and many other high-performance applications.
Located in San Diego, California – Express Logic’s mission is to provide the absolute best quality software solutions for deeply embedded applications. In addition to providing the very best software products, we philosophically believe in licensing our products in a non-royalty fashion along with providing complete source code. This combination of having superior products and a practical business model is paying huge dividends. The name recognition and popularity of ThreadX is growing tremendously from year to year.
ThreadX is Express Logic’s advanced Real-Time Operating System (RTOS) designed specifically for deeply embedded applications. ThreadX has many advanced features, including its picokernel™ architecture, preemption-threshold,™ event-chaining,™ and a rich set of system services. Combined with its superior ease-of-use, ThreadX is the ideal choice for the most demanding of embedded applications.
The Design Enablement Network, formerly called the GLOBALSOLUTIONS Ecosystem, encompasses IP, EDA, Design Services, OSAT and specialized FDX and RF networks.
Semiconductor Manufacturing International Corporation (“SMIC”; NYSE: SMI; SEHK: 981) is one of the leading semiconductor foundries in the world and the largest and most advanced foundry in mainland China. SMIC provides integrated circuit (IC) foundry and technology services at 0.35-micron to 40-nanometer and has begun offering advanced 28nm process technology. Headquartered in Shanghai, China, SMIC has a 300mm wafer fabrication facility (fab) and a 200mm mega-fab in Shanghai, a 300mm mega-fab in Beijing, a 200mm fab inTianjin, and a 200mm fab project under development in Shenzhen. SMIC also has customer service and marketing offices in the U.S.,Europe, Japan, and Taiwan, and a representative office in Hong Kong.
The Bluetooth SIG is a global community of over 34,000 companies serving to unify, harmonize and drive innovation in the vast range of connected devices all around us.
The Car Connectivity Consortium brings automotive and consumer technology industries together to future-proof vehicle access using smart devices. Every significant manufacturer in every corner of the world — from Shanghai, China to Munich, Germany to New York City, USA — is a vital part of our member-based organization. Secure shareability is not just one of the unique aspects of the CCC Digital Key — it’s the foundation of our organization. With membership comes a seat at our table, no matter the size of your company or nonprofit, and an equal say in the gold standard of end-to-end interoperability. Cross-platform compatibility is our brand promise, so everyone globally can experience the same access to private, secure mobility.
The FiRa Consortium is dedicated to the development and widespread adoption of seamless user experiences using the secured fine ranging and positioning capabilities of interoperable Ultra-Wideband (UWB) technologies.
The International Wireless Industry Consortium.We facilitate global knowledge-capital collaboration, delivering unfiltered real time insight into vital technology, market and ecosystem evolution.
O-RAN ALLIANCE members and contributors have committed to evolving radio access networks around the world. Future RANs will be built on a foundation of virtualized network elements, white-box hardware and standardized interfaces that fully embrace O-RAN’s core principles of intelligence and openness. An ecosystem of innovative new products is already emerging that will form the underpinnings of the multi-vendor, interoperable, autonomous RAN, envisioned by many in the past, but only now enabled by the global industry-wide vision, commitment and leadership of O-RAN ALLIANCE members and contributors.
Wi-Fi Alliance® is the worldwide network of companies that brings you Wi-Fi®, one of the world’s most valued communications technologies. Our vision is to connect everyone and everything, everywhere.
The ChipEstimate.com chip planning portal is an ecosystem comprised of over 200 of the world's largest semiconductor design and verification IP suppliers and foundries. These companies all share in the common vision of helping the worldwide electronics design community achieve greater profitability and success. To date, a diverse global audience of over 45,000 users has joined the ChipEstimate.com community. ChipEstimate.com is a property of Cadence Design Systems, Inc. (NASDAQ: CDNS), the leader in global electronic-design innovation.
Design And Reuse (D&R) was founded in 1997 to promote the Intellectual Property (IP) concept in Electronic Systems. Its efforts led first to the creation of a worldwide B2B portal. D&R, as a software vendor, licenses IP packaging and IP exchange intranet technology through 4 products namely IP Provider Station, IP intranet Consumer Station, IP Intranet Reuse Station and recently SoC Collaborative station.
Partner Type
Media partners
CEVA IP supported
All CEVA DSP cores and platforms
Product Offering
Based on its early experience, D&R licenses technology and services to make IP sharing and reuse happen worldwide and in each electronic design enterprise through 3 major products.
To IP providers, D&R offers the best vehicle (IP ProviderSstation) for publishing their offers through electronic catalogs, packaging their IPs and optimizing their delivery to customers while providing outstanding customer support. Automated catalog update, easy and efficient client data base management, and reliable IP delivery process will allow them to save resources while creating the best communication channel to their customers for mutual satisfaction; This will let them focus more resources on their excellence domain which is the IP design.
For large intranet corporations, D&R offers an innovative technology (IP consumer Intranet station) for organizing intranet catalogs for pre qualified external supplier and installing IP delivery stations for external suppliers under corporate contract; This will give a better insight to Asic project designers for selecting and using external suppliers and will drastically save time to market for their best Asic designs.
Finally D&R delivers to large corporations the Premier internal reuse station (IP reuse Intranet Station) so efficient and so easy to use that designers can exchange their reusable blocks with close to no overhead.
Within large corporations, information and IP source sharing of internal Intellectual property will become a reality by using D&R Technology; D&R believes that the Electronic design enterprise platforms have to be envisioned and implemented with the help and through the vision of experienced electronic design players in order to fully capture the needs of this community.
The Embedded Vision Alliance™ is a worldwide industry partnership that brings together technology providers who are enabling innovative and practical applications for computer vision. Its more than 50 members include suppliers of processors, sensors, software and services.Founded in 2011, the Alliance is led by Berkeley Design Technology, Inc. (BDTI), an independent technology analysis and engineering services firm. BDTI manages the Alliance on behalf of the member companies.
Partner Type
Media partners
Product Offering
The mission of the Alliance is two-fold:
Inspire and empower product creators to incorporate visual intelligence into new products and applications, and
Enable Alliance member companies to accelerate success in computer vision by:
Increasing their visibility among vision system and application developers
Connecting them with the right ecosystem partners, and
Delivering insights into market research, technology trends, and customer requirements
SemiWiki.com, the open forum for semiconductor professionals, is a leading online community of people involved with electronic devices and the semiconductor design and manufacturing ecosystem.
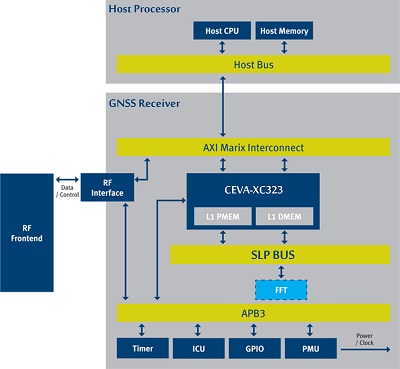
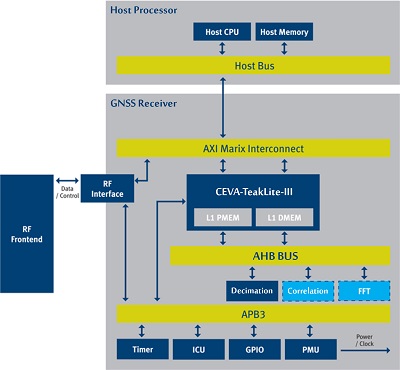
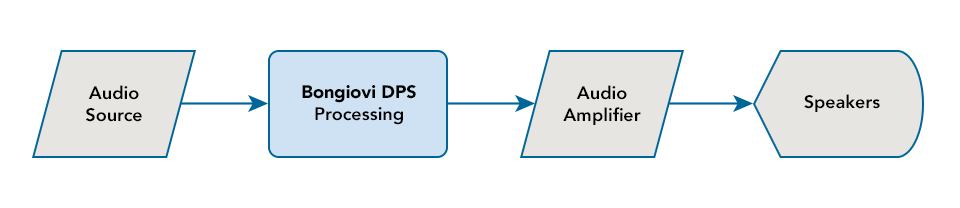
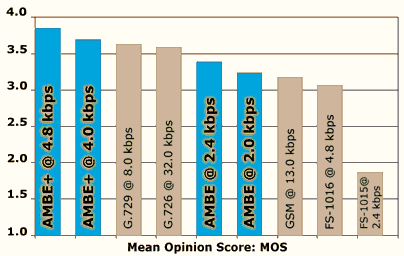 AMBE+2™ 2.0 – 9.6 kbps DVSI’s latest technology featuring toll-quality, full-duplex, real-time voice compression software
AMBE+2™ 2.0 – 9.6 kbps DVSI’s latest technology featuring toll-quality, full-duplex, real-time voice compression software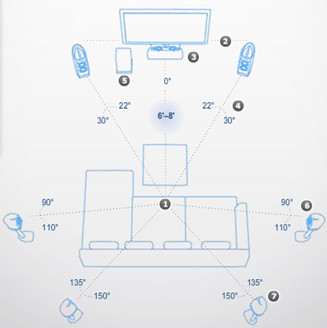 Multi-stream, multi-channel audio codecs:
Multi-stream, multi-channel audio codecs: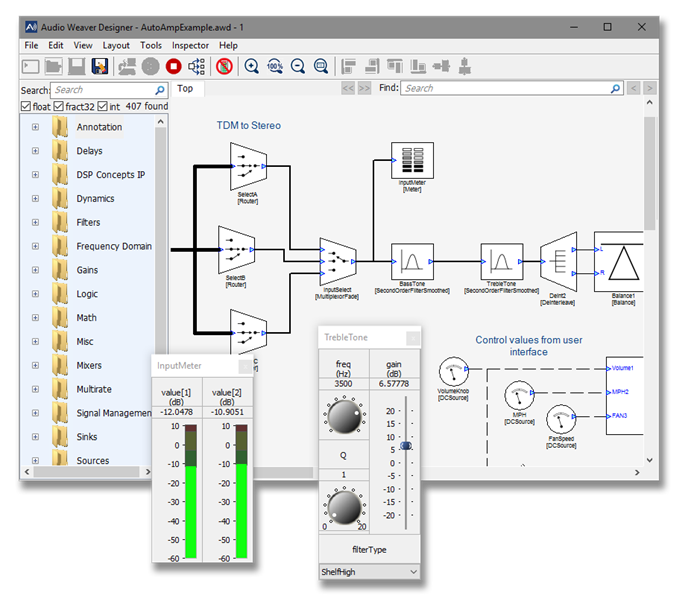
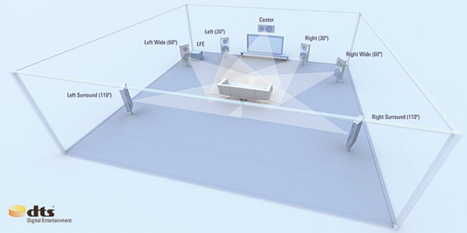 Multi-stream, multi-channel audio codecs:
Multi-stream, multi-channel audio codecs: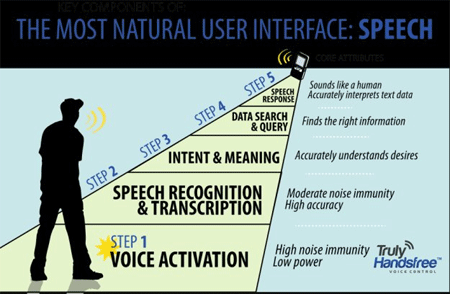 Sensory’s TrulyHandsfree™ Voice Control technology builds upon the initial success of TrulyHandsfree™ Trigger, and now offers multiple phrase technology that recognizes, analyzes and responds to dozens of keywords. It consistently recognizes phrases even when embedded in sentences and surrounded by noise. Traditional approaches to keyword spotting have failed in high noise and frequently false fire, but TrulyHandsfree™ has excellent accuracy without false fires even in high noise and speech. Smartphones, Bluetooth devices and consumer electronics for the home and the car can now offer a TrulyHandsfree experience from beginning to end. The fully programmable CEVA-TeakLite-4 DSP enables the lowest power TrulyHandsfree implementation in the market, while leaving plenty of headroom to support other audio/voice related functions in software.
Sensory’s TrulyHandsfree™ Voice Control technology builds upon the initial success of TrulyHandsfree™ Trigger, and now offers multiple phrase technology that recognizes, analyzes and responds to dozens of keywords. It consistently recognizes phrases even when embedded in sentences and surrounded by noise. Traditional approaches to keyword spotting have failed in high noise and frequently false fire, but TrulyHandsfree™ has excellent accuracy without false fires even in high noise and speech. Smartphones, Bluetooth devices and consumer electronics for the home and the car can now offer a TrulyHandsfree experience from beginning to end. The fully programmable CEVA-TeakLite-4 DSP enables the lowest power TrulyHandsfree implementation in the market, while leaving plenty of headroom to support other audio/voice related functions in software.


 The ARM RealView Developer Suite multi-core debug solution provides the facility to debug multiple ARM plus DSP cores using a single debug environment. The RealView multi-core debug tools consist of:
The ARM RealView Developer Suite multi-core debug solution provides the facility to debug multiple ARM plus DSP cores using a single debug environment. The RealView multi-core debug tools consist of: CMX-RTX is a truly preemptive, multi-tasking RTOS supporting the Palm and Teaklite series of processors. This “lean and mean” RTOS offers the smallest footprint, the fastest context switching times, and the lowest interrupt latency times available on the market today. CMX-RTX is licensed with a low, one-time fee and features full source code, no royalties on shipped products and free technical support and software updates.
CMX-RTX is a truly preemptive, multi-tasking RTOS supporting the Palm and Teaklite series of processors. This “lean and mean” RTOS offers the smallest footprint, the fastest context switching times, and the lowest interrupt latency times available on the market today. CMX-RTX is licensed with a low, one-time fee and features full source code, no royalties on shipped products and free technical support and software updates.